Indent line 16 by four spaces, just like line 12.
"""
Reverse a string using a generator.
"""
import sys
def reverseString(testString):
"Yield the characters of the string in reverse order."
for c in reversed(str(testString)):
yield c
for char in reverseString("Google"):
print(char)
sys.exit(0)
e l g o o G
"""
Reverse a string using recursion.
"""
import sys
def reverse(s):
"Return the string reversed."
return s if len(s) < 2 else reverse(s[1:]) + s[0]
print(reverse("Google"))
sys.exit(0)
elgooG
Simplify lines 85–86 from
self.day = Date.lengths[self.month - 1]
self.month -= 1
to
self.month -= 1
self.day = Date.lengths[self.month]
Line
28
should be the only place in the program where the length of December is
written.
Change the
31
hardcoded into
line
88
to
Date.lengths[-1].
And while you’re at it, change the
12
hardcoded into
line
89
to
Date.monthsInYear().
Indent with groups of
four
spaces.
A non-interactive program (i.e., one that does not call
input)
should send its error messages to
sys.stderr.
The error message should include the exception that was raised,
because maybe the exception will tel you precisely what went wrong.
Read the URLs from a file.
Call
urlparse
between
try
and
except.
If the
netloc
was equal to
"www.",
would the original program print it?
"""
Remove trash before and after any given URL e.g. https//,www,http
as well as removing duplicate URLs.
Currently pulls domains.
"""
import sys
from urllib.parse import urlparse
URLS = [
"https://www.eeweb.com/profile/max-maxfield/articles/are-you-ready-for-ces-2019",
"http://www.computing.es/mundo-digital/opinion/1109416046601/cinco-tendencias-del-ces-2019.1.html",
"https://innovadores.larazon.es/es/not/las-cinco-tendencias-del-ces-2019-del-5g-a-la-realidad-inmersiva",
"https://www.revistabyte.es/actualidad-byte/cinco-tendencias-ces-2019/",
"https://www.eweek.com/innovation/why-ces-2019-will-star-5g-immersive-reality-digital-trust-voice-ui",
"Print Only",
"https://www.iot-now.com/2019/01/10/91968-smart-speaker-usage-booms-worldwide-trust-key-continued-adoption-says-accenture/",
"https://www.informationweek.com/strategic-cio/digital-business/platforms-where-the-digital-and-physical-worlds-meet/a/d-id/1334255",
"https://www.techdigest.tv/2019/01/smart-speaker-usage-booming-worldwide-accenture-study-finds.html",
"https://www.androidheadlines.com/2019/01/smart-speaker-usage-study-2019.html",
"https://www.computerweekly.com/news/252455444/Smart-speakers-set-to-own-the-consumer-ecosystem",
"https://www.mediaplaynews.com/study-standalone-voice-assistants-one-of-fastest-adopted-technologies-in-u-s-history/",
"https://www.globalbankingandfinance.com/smart-speaker-usage-booming-worldwide-accenture-study-finds/",
"https://www.barrons.com/articles/big-tech-to-consumers-you-can-trust-us-really-51546980034?mod=bol-social-tw",
"https://telecom.economictimes.indiatimes.com/news/smart-speakers-have-97-satisfaction-rate-in-india-accenture/67455270",
"https://gadgets.ndtv.com/tv/news/smart-speakers-have-97-percent-satisfaction-rate-in-india-accenture-1975249",
"https://www.timesnownews.com/technology-science/article/smart-speakers-one-of-the-fastest-adopted-technologies-have-97-satisfaction-rate-in-india-accenture/344537",
"https://www.pcquest.com/smart-speaker-usage-booming-india-accenture-study-finds/",
"https://www.telegraph.co.uk/technology/2019/01/10/ces-2019-tvs-have-become-new-battleground-tech-giants/",
"https://finance.yahoo.com/video/battle-smart-speakers-003509711.html",
"https://itbrief.co.nz/story/reshape-to-relevance-accenture-s-2019-consumer-survey",
"https://voicebot.ai/2019/01/14/alexa-automotive-news-round-up-ces-2019/",
"https://itbrief.com.au/story/reshape-to-relevance-accenture-s-2019-consumer-survey",
"https://futurefive.co.nz/story/reshape-to-relevance-accenture-s-2019-consumer-survey",
"https://channellife.co.nz/story/reshape-to-relevance-accenture-s-2019-consumer-survey",
"https://finance.yahoo.com/news/how-amazon-alexa-is-winning-the-smart-assistant-race-193904486.html",
"https://www.theaustralian.com.au/life/personal-technology/help-with-routine-activities-is-increasingly-as-easy-as-asking-a-device/news-story/ab4aa6a39048d16ed9e4f43302fc26f3",
"https://www.business-standard.com/article/specials/online-consumers-in-india-are-clearly-ahead-of-the-global-average-study-119011601372_1.html",
"https://www.gadgetguy.com.au/accenture-survey-shows-we-are-a-talkative-lot/",
"https://www.itwire.com/home-it/85768-australian-use-of-dvas-increasing,-accenture-survey-claims.html",
"https://www.techshout.com/gadgets/2019/23/smart-home-speakers-take-india-by-storm/",
"https://www.vanillaplus.com/2019/01/23/44614-speak-digital-virtual-assistants-open-door-ai-csps/",
"https://geekpopsite.wordpress.com/2019/01/28/accenture-confirma-las-tecnologias-cuyo-uso-esta-creciendo-entre-los-consumidores/",
"http://www.webretail.news/index.php/info-rss/3546-pisan-fuerte"
]
for url in URLS:
try:
parsed_object = urlparse(url)
except BaseException as error:
print(f"Something went wrong when trying to parse URLS: {error}", file = sys.stderr)
sys.exit(1)
netloc = parsed_object.netloc
if netloc.startswith('www.'):
print(netloc[4:])
elif netloc != '':
print(netloc)
sys.exit(0)
Simpler with regular expressions:
import re #regular expressions
netloc = parsed_object.netloc
if netloc != "":
netloc = re.sub(r"^www\.", "", netloc) #remove leading "www."
print(netloc)
Remove duplicates.
netlocs
is a
set
of
strings
created with a set comprehension.
Unfortunately, the set comprehension has to call
urlparse
twice during each iteration.
netlocs = {
re.sub(r"^www\.", "", urlparse(url).netloc)
for url in URLS
if urlparse(url).netloc != ""
}
for netloc in netlocs:
print(netloc)
Python 3.8 example.
Once again,
netlocs
is a
set
of
strings.
But now the set comprehension can get away with calling
urlparse
only once per iteration
thanks to the walrus operator
:=.
netlocs = {
re.sub(r"^www\.", "", netloc)
for url in URLS
if (netloc := urlparse(url).netloc) != ""
}
for netloc in netlocs:
print(netloc)

Suppose we had a
Date
object containing December 1, 2019.
The
prevDay
method in
lines
99–110
should change this
Date
to November 30, 2019.
Let’s see what actually happens.
Line
105
changes
self.month
from 12 to 11.
Then
line
106
puts
Date.lengths[10]
into
self.day.
But
Date.lengths[10]
is 31, so the
Date
object ends up holding the illegal value November 31, 2019.
Also: simplify lines 108–109 from
self.month = len(Date.lengths) - 1
self.day = Date.lengths[len(Date.lengths) - 1]
to
self.month = len(Date.lengths) - 1
self.day = Date.lengths[self.month]
or to
self.month = len(Date.lengths) - 1
self.day = Date.lengths[-1]
Make lines 25–39 easier to check:
states = [
['Virginia',1607],
['New York',1626],
['Massachusetts',1630],
['Maryland',1633],
['Rhode Island',1636],
['Connecticut',1636],
['New Hampshire',1638],
['Delaware',1638],
['North Carolina',1653],
['South Carolina',1663],
['New Jersey',1664],
['Pennsylvania',1682],
['Georgia',1732]
]
Easier to see that the years are in chronological order.
Makes Georgia stand out:
states = [
[1607, 'Virginia'],
[1626, 'New York'],
[1630, 'Massachusetts'],
[1633, 'Maryland'],
[1636, 'Rhode Island'],
[1636, 'Connecticut'],
[1638, 'New Hampshire'],
[1638, 'Delaware'],
[1653, 'North Carolina'],
[1663, 'South Carolina'],
[1664, 'New Jersey'],
[1682, 'Pennsylvania'],
[1732, 'Georgia'] #Wikipedia says 1733
]
Then change
0
to
1
in
line
41,
and add
reversed
to
line
45:
states = [StateFacts(*reversed(state)) for state in states]
Change the message in
line
13
to
"state name must be string"
to match the other message in
line
18.
When a function complains about an argument,
it should specify which argument.
It wastes space and time to print a space at the end of a line in lines 47 and 49.
Misleading varable names.
The
verifyingList
in
line
38
is a
string,
not a
list.
The
verifyingList
in
line
39
is a
set,
not a
list.
The
dictionary
in
line
42
should be a (two-dimensional)
list
because we merely loop through it.
We never look up any key.
Even better,
combine the three
strings
in
line
42
with the three expressions in
line
41
into the following
listOftests.
"""
ingredientanalysis.py
Report whether each input ingredient belongs to one or neither
of two disjoint sets.
"""
import sys
import urllib.request
instructions = """\
Check list of ingredients against internal ingredient database
for possible allergic reaction. Please enter list of ingredients
in lowercase, separated by a comma and a space. """
safeIngredients = {
"talc", #dior
"nylon-12",
"mica",
"barium sulfate",
"phenyl trimethicone",
"caprylyl glycol",
"titanium dioxide"
}
potentialAllergens = {
"kaolin", #kvd
"magnesium myristate",
"boron nitride",
"isoamyl laurate",
"zinc stearate",
"polyester-4",
"2-hexanediol",
"dimethiconol",
"oryza sativa hull powder",
"iron oxide"
}
#assert len(safeIngredients & potentialAllergens) == 0 #Must be disjoint.
assert safeIngredients.isdisjoint(potentialAllergens) #A simpler way to do the same thing.
def hasWiki(ingredient):
"Return True if this ingredient has a Wikipedia article."
ingredient = ingredient.replace(" ", "_").capitalize()
url = f"https://en.wikipedia.org/wiki/{ingredient}"
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError:
return False
else:
infile.close()
return True
#In the following lambda functions, s is a set of strings that are ingredients.
#Each lambda function returns a subset of s.
listOfTests = [
["safe", lambda s: s & safeIngredients],
["potentially allergic", lambda s: s & potentialAllergens],
["unknown", lambda s: s - safeIngredients - potentialAllergens],
["possibly misspelled", lambda s: {ingredient for ingredient in s if not hasWiki(ingredient)}]
]
def convert(string):
"Split the argument into a set of names of ingredients."
return set(string.split(", "))
stringOfIngredients = input(instructions)
setOfIngredients = convert(stringOfIngredients)
print()
for description, test in listOfTests: #description is a str, test is a function
subsetOfIngredients = test(setOfIngredients)
if len(subsetOfIngredients) != 0:
singular = len(subsetOfIngredients) == 1 #singular is True or False.
verb = "is" if singular else "are"
suffix = "" if singular else "s"
print(f"There {verb} {len(subsetOfIngredients)} {description} ingredient{suffix}:")
for i, ingredient in enumerate(subsetOfIngredients, start = 1):
print(f"{i:2}. {ingredient}")
print()
sys.exit(0)
Check list of ingredients against internal ingredient database for possible allergic reaction. Please enter list of ingredients in lowercase, separated by a comma and a space. talc, iron oxide, mica, tin There are 2 safe ingredients: 1. talc 2. mica There is 1 potentially allergic ingredient: 1. iron oxide There is 1 unknown ingredient: 1. tin
"""
A class where most of the attributes are optional.
"""
import sys
# Create class
class State:
"An instance of this class contains 1 required and 4 optional attributes."
def __init__(self, name, governor = None,
ltGovernor = None, capital = None, largestCity = None):
"Instantiate a new object of class State. Only the name is required."
self.name = name
self.governor = governor
self.ltGovernor = ltGovernor
self.capital = capital
self.largestCity = largestCity
def __str__(theState):
"Return a str showing all the information in theState."
s = theState.name
optionalAttributes = ["governor", "ltGovernor", "capital", "largestCity"]
for optionalAttribute in optionalAttributes:
value = getattr(theState, optionalAttribute)
if value is not None:
s += f", {optionalAttribute} = {value}"
return s
#Create and print two objects.
ny = State("New York", governor = "Cuomo", ltGovernor = "Hochul",
capital = "Albany", largestCity = "New York City")
nj = State("New Jersey", capital = "Trenton", largestCity = "Newark")
print(__str__(ny))
print(__str__(nj))
print()
#Mass produce many instances of class State. Store them in a list.
stateInfos = [
["Alabama", {"capital": "Montgomery", "largestCity": "Birmingham"}],
["Alaska", {"capital": "Juneau", "largestCity": "Anchorage"}],
["Arizona", {"largestCity": "Phoenix"}],
["Arkansas", {}], #empty dictionary
["California", {"capital": "Sacramento"}]
]
listOfStates = [State(name, **d) for name, d in stateInfos]
for state in listOfStates:
print(__str__(state))
sys.exit(0)
New York, governor = Cuomo, ltGovernor = Hochul, capital = Albany, largestCity = New York City New Jersey, capital = Trenton, largestCity = Newark Alabama, capital = Montgomery, largestCity = Birmingham Alaska, capital = Juneau, largestCity = Anchorage Arizona, largestCity = Phoenix Arkansas California, capital = Sacramento
E-mail Address 1: 'BritanyTalley@gmail.com' 2: 'LulaBrandt@outlook.com' 3: 'WoodyHodges@outlook.com' 4: 'DeonPark@yahoo.com' 5: 'LawsonMedrano@gmail.com' Hide E-mail Address 1: 'B***********y@gmail.com' 2: 'L********t@outlook.com' 3: 'W*********s@outlook.com' 4: 'D******k@yahoo.com' 5: 'L***********o@gmail.com'
No reason to search for the
@
twice in each email address.
Remove
line
16
and change the
idx
to
i
in
line
20.
It’s a waste of time for the
for
loop in
lines
17–19
to keep iterating after it has found the
"@".
Insert a
break
statement under
line
19,
indented the same distance as line 19.
Parentheses unnecessary in lines
18
and
20.
The
0,
is unnecessary in
line 17.
A plain old
list
is simpler than a
dictionary
whose keys are consecutive integers.
Simpler to use a
formatted
string
instead of the
format
method.
No reason to call
repr;
see
!r
in
Format
String Syntax.
"""
Function to hide e-mail address.
"""
import sys
listOfAddresses = [
'BritanyTalley@gmail.com',
'LulaBrandt@outlook.com',
'WoodyHodges@outlook.com',
'DeonPark@yahoo.com',
'LawsonMedrano@gmail.com'
]
def hideEmail(address):
'Disembowel the username of an email address. Return unchanged if wrong number of "@"s.'
if address.count("@") != 1:
return address
i = address.index("@")
return address[0] + (i-2) * "*" + address[i-1:]
listOfHiddenAddresses = [hideEmail(address) for address in listOfAddresses]
print('E-mail Address')
for i, address in enumerate(listOfAddresses, start = 1):
print(f"{i}: '{address}'")
print('Hide E-mail Address')
for i, hiddenAddress in enumerate(listOfHiddenAddresses, start = 1):
print(f"{i}: '{hiddenAddress}'")
sys.exit(0)
Substitute using
regular expressions.
match
is a
Match
object.
import re #regular expressions
def hideEmail(address):
'Disembowel the username of an email address. Return unchanged if wrong number of "@"s.'
if address.count("@") != 1:
return address
return re.sub("(?<=.)(.*)(?=.@)", lambda match: len(match[1]) * "*", address)
At 8:00 a.m. EDT on Tuesday, October 29, 2019,
I got the following
KeyError
because at that time the dictionary
bigDictionary["Time Series (Daily)"]
did not have the key
"2019-10-29".
Microsoft (MSFT) High/Low:
Traceback (most recent call last):
File "/Users/myname/python/junk.py", line 77, in <module>
print(f'Today\'s High: $ {bigDictionary["Time Series (Daily)"][today]["2. high"]}')
KeyError: '2019-10-29'
Simpler way to compute
yest
instead of
lines
43–47:
#Stock market is open only weekdays.
if tod.weekday() == 0: #if today is Monday
days = 3 #go back 3 days to the previous Friday
else:
days = 1
delta = datetime.timedelta(days = days)
yest = (tod - delta).strftime("%Y-%m-%d")
"""
MSFT_quotes.py
Reads JSON file and prints today's, yesterday's and avg stock prices for MSFT.
"""
import sys
import urllib.parse
import urllib.request
import json
import datetime
import statistics
import pandas as pd
query = {
"apikey": "demo",
"function": "TIME_SERIES_DAILY_ADJUSTED",
"symbol": "MSFT" #Microsoft
}
params = urllib.parse.urlencode(query)
url = f"https://www.alphavantage.co/query?{params}"
#Read in JSON file
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = infile.read() #Read the entire input file.
infile.close()
try:
s = sequenceOfBytes.decode("utf-8") #s is a string.
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
try:
bigDictionary = json.loads(s) #bigDictionary is a dict
except json.JSONDecodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
try:
dailyDict = bigDictionary['Time Series (Daily)']
except KeyError as error:
print(error, file = sys.stderr)
sys.exit(1)
#Get the two most recent dates in the time series.
dates = dailyDict.keys()
dates = sorted(dates, key = lambda d: datetime.datetime.strptime(d, "%Y-%m-%d")) #chronological order
today = dates[-1] #The latest date is at the very end.
yest = dates[-2] #Next-to-latest date. Can combine to yest, today = dates[-2:]
#Compute the average high and low using Python.
hiList = [float(value["2. high"]) for value in dailyDict.values()]
loList = [float(value["3. low"]) for value in dailyDict.values()]
hiAvg = statistics.mean(hiList)
loAvg = statistics.mean(loList)
print(f"hiAvg = $ {hiAvg:.4f}")
print(f"loAvg = $ {loAvg:.4f}")
print()
#Compute the average high and low using pandas.
df = pd.DataFrame(dailyDict)
avg_hi = df.loc['2. high'].astype(float).mean()
avg_lo = df.loc['3. low' ].astype(float).mean()
print("Microsoft (MSFT) High/Low:")
print()
#TODAY'S PRICES
print(f"today = {today}")
todaysPrices = dailyDict[today]
print(f'Today\'s High: $ {todaysPrices["2. high"]}')
print(f'Today\'s Low: $ {todaysPrices["3. low"]}')
print()
#Previous Day's PRICES
print(f"yesterday = {yest}")
yesterdaysPrices = dailyDict[yest]
print(f'Prev Day\'s High: $ {yesterdaysPrices["2. high"]}')
print(f'Prev Day\'s Low: $ {yesterdaysPrices["3. low"]}')
print()
#Average high/low from entire JSON file: includes roughly ~40 weekdays or 2 months
print(f'2 Mo. High Avg: $ {avg_hi:.4f}')
print(f'2 Mo. Low Avg: $ {avg_lo:.4f}')
#Tried to do a 30 day average instead of the whole JSON file but too advanced, couldn't figure it out
#print(f'30 day High Avg: $ {hiAvg:.4f}')
#print(f'30 day Low Avg: $ {loAvg:.4f}')
sys.exit(0)
hiAvg = $ 138.2282 loAvg = $ 136.0418 Microsoft (MSFT) High/Low: today = 2019-10-28 Today's High: $ 145.6700 Today's Low: $ 143.5100 yesterday = 2019-10-25 Prev Day's High: $ 141.1400 Prev Day's Low: $ 139.2000 2 Mo. High Avg: $ 138.2282 2 Mo. Low Avg: $ 136.0418
By 10:15 a.m. an entry for
"2019-10-29"
had appeared:
hiAvg = $ 138.3507 loAvg = $ 136.1957 Microsoft (MSFT) High/Low: today = 2019-10-29 Today's High: $ 144.5000 Today's Low: $ 143.6433 yesterday = 2019-10-28 Prev Day's High: $ 145.6700 Prev Day's Low: $ 143.5100 2 Mo. High Avg: $ 138.3507 2 Mo. Low Avg: $ 136.1957
Lucky that each movie name is a single word.
The program produces no output becuase we never print the return value of
the function
get_movie_data
in
line
32.
The
for
loop in
line
17
iterates only once because of the
return
in
line
29.
Never write a loop that always iterates exectly once.
import sys
import requests
import pandas as pd
import tkinter
import PIL.ImageTk #Python Imaging Library: pip3 install pillow
import urllib.request
def get_movie_data(listOfNames):
"Return a list containing dictionaries of information about movies."
listofmovies = []
for name in listOfNames:
url = f"http://projects.bobbelderbos.com/pcc/omdb/{name}.json"
with requests.Session() as session: #will close the session when done with it
try:
response = session.get(url)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
dict_object = response.json()
listofmovies.append(dict_object)
return listofmovies
stringOfNames = 'bladerunner2049 fightclub glengary horrible-bosses terminator'
listOfNames = stringOfNames.split()
listOfDictionaries = get_movie_data(listOfNames)
for movie in listOfDictionaries:
print(movie)
print()
#Display the information in a pandas DataFrame.
columns = ["Title", "Year", "Rated", "Runtime", "Genre"]
dictionaryOfColumns = {
column: [movie[column] for movie in listOfDictionaries]
for column in columns
}
df = pd.DataFrame(data = dictionaryOfColumns)
print(df)
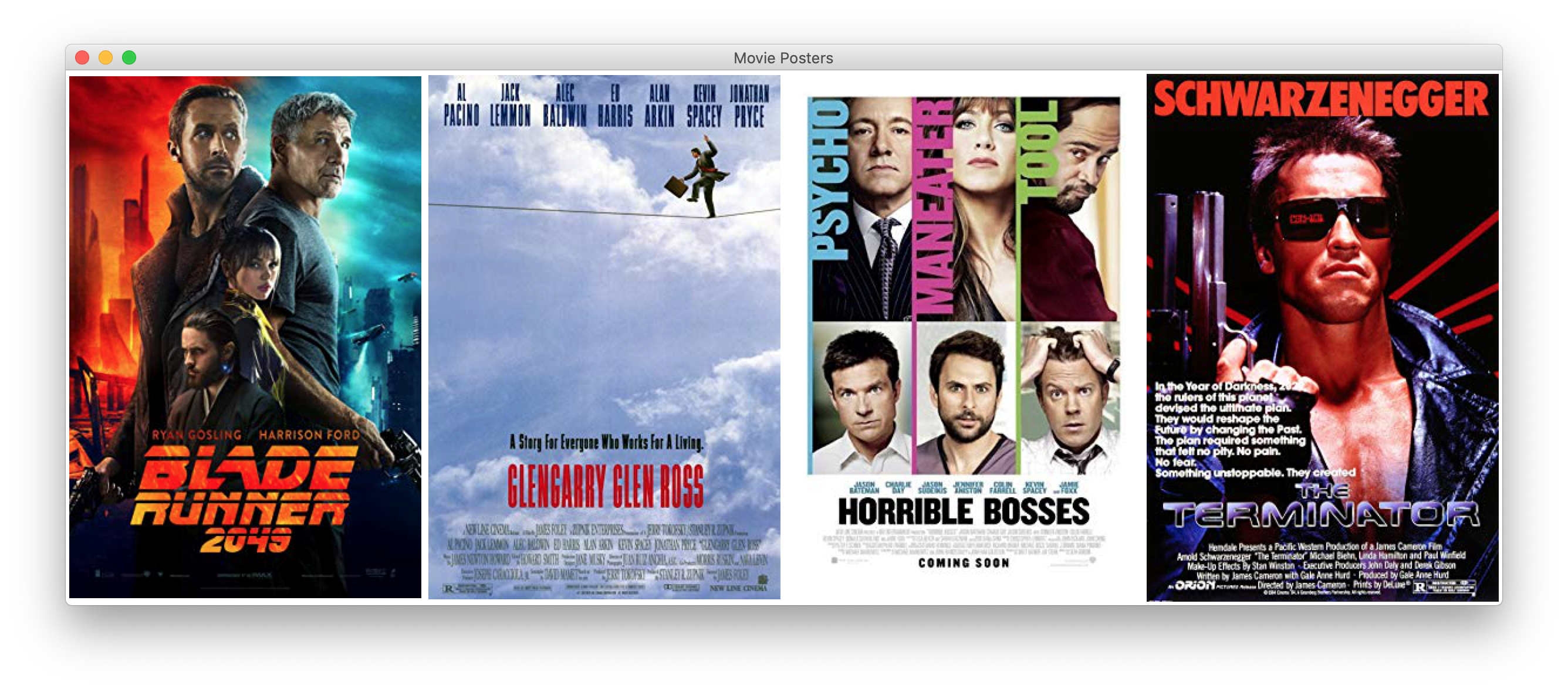
#Display the posters in a tkinter interface.
root = tkinter.Tk()
root.title("Movie Posters")
for movie in listOfDictionaries:
url = movie["Poster"]
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
if error.msg == "Not Found":
continue
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = infile.read()
infile.close()
try:
image = PIL.ImageTk.PhotoImage(data = sequenceOfBytes)
except tkinter.TclError as error:
print(error, file = sys.stderr)
sys.exit(1)
label = tkinter.Label(root, image = image)
label.image = image #Strange that you need this too.
label.pack(side = tkinter.LEFT) #Fill the root from left to right.
root.mainloop()
{'Title': 'Blade Runner 2049', 'Year': '2017', 'Rated': 'R', 'Released': '06 Oct 2017', 'Runtime': '164 min', 'Genre': 'Mystery, Sci-Fi, Thriller', 'Director': 'Denis Villeneuve', 'Writer': 'Hampton Fancher (screenplay by), Michael Green (screenplay by), Hampton Fancher (story by), Philip K. Dick (based on characters from the novel "Do Androids Dream of Electric Sheep?")', 'Actors': 'Ryan Gosling, Dave Bautista, Robin Wright, Mark Arnold', 'Plot': "A young blade runner's discovery of a long-buried secret leads him to track down former blade runner Rick Deckard, who's been missing for thirty years.", 'Language': 'English, Finnish, Japanese, Hungarian, Russian, Somali, Spanish', 'Country': 'USA, UK, Hungary, Canada', 'Awards': '6 wins & 13 nominations.', 'Poster': 'https://images-na.ssl-images-amazon.com/images/M/MV5BNzA1Njg4NzYxOV5BMl5BanBnXkFtZTgwODk5NjU3MzI@._V1_SX300.jpg', 'Ratings': [{'Source': 'Internet Movie Database', 'Value': '8.4/10'}, {'Source': 'Rotten Tomatoes', 'Value': '87%'}, {'Source': 'Metacritic', 'Value': '81/100'}], 'Metascore': '81', 'imdbRating': '8.4', 'imdbVotes': '156,246', 'imdbID': 'tt1856101', 'Type': 'movie', 'DVD': 'N/A', 'BoxOffice': '$89,276,502', 'Production': 'Warner Bros. Pictures', 'Website': 'http://bladerunnermovie.com', 'Response': 'True'}
{'Title': 'Fight Club', 'Year': '1999', 'Rated': 'R', 'Released': '15 Oct 1999', 'Runtime': '139 min', 'Genre': 'Drama', 'Director': 'David Fincher', 'Writer': 'Chuck Palahniuk (novel), Jim Uhls (screenplay)', 'Actors': 'Edward Norton, Brad Pitt, Meat Loaf, Zach Grenier', 'Plot': 'An insomniac office worker, looking for a way to change his life, crosses paths with a devil-may-care soap maker, forming an underground fight club that evolves into something much, much more.', 'Language': 'English', 'Country': 'USA, Germany', 'Awards': 'Nominated for 1 Oscar. Another 10 wins & 32 nominations.', 'Poster': 'https://images-na.ssl-images-amazon.com/images/M/MV5BZGY5Y2RjMmItNDg5Yy00NjUwLThjMTEtNDc2OGUzNTBiYmM1XkEyXkFqcGdeQXVyNjU0OTQ0OTY@._V1_SX300.jpg', 'Ratings': [{'Source': 'Internet Movie Database', 'Value': '8.8/10'}, {'Source': 'Rotten Tomatoes', 'Value': '79%'}, {'Source': 'Metacritic', 'Value': '66/100'}], 'Metascore': '66', 'imdbRating': '8.8', 'imdbVotes': '1,508,138', 'imdbID': 'tt0137523', 'Type': 'movie', 'DVD': '06 Jun 2000', 'BoxOffice': 'N/A', 'Production': '20th Century Fox', 'Website': 'http://www.foxmovies.com/fightclub/', 'Response': 'True'}
{'Title': 'Glengarry Glen Ross', 'Year': '1992', 'Rated': 'R', 'Released': '02 Oct 1992', 'Runtime': '100 min', 'Genre': 'Crime, Drama, Mystery', 'Director': 'James Foley', 'Writer': 'David Mamet (play), David Mamet (screenplay)', 'Actors': 'Al Pacino, Jack Lemmon, Alec Baldwin, Alan Arkin', 'Plot': 'An examination of the machinations behind the scenes at a real estate office.', 'Language': 'English', 'Country': 'USA', 'Awards': 'Nominated for 1 Oscar. Another 6 wins & 10 nominations.', 'Poster': 'https://images-na.ssl-images-amazon.com/images/M/MV5BNTYzN2MxODMtMDBhOC00Y2M0LTgzMTItMzQ4NDIyYWIwMDEzL2ltYWdlL2ltYWdlXkEyXkFqcGdeQXVyNTc1NTQxODI@._V1_SX300.jpg', 'Ratings': [{'Source': 'Internet Movie Database', 'Value': '7.8/10'}, {'Source': 'Rotten Tomatoes', 'Value': '94%'}, {'Source': 'Metacritic', 'Value': '80/100'}], 'Metascore': '80', 'imdbRating': '7.8', 'imdbVotes': '83,208', 'imdbID': 'tt0104348', 'Type': 'movie', 'DVD': '20 Feb 2007', 'BoxOffice': 'N/A', 'Production': 'Artisan Home Entertainment', 'Website': 'http://www.artisanent.com/glengarryglenross', 'Response': 'True'}
{'Title': 'Horrible Bosses', 'Year': '2011', 'Rated': 'R', 'Released': '08 Jul 2011', 'Runtime': '98 min', 'Genre': 'Comedy, Crime', 'Director': 'Seth Gordon', 'Writer': 'Michael Markowitz (screenplay), John Francis Daley (screenplay), Jonathan Goldstein (screenplay), Michael Markowitz (story)', 'Actors': 'Jason Bateman, Steve Wiebe, Kevin Spacey, Charlie Day', 'Plot': 'Three friends conspire to murder their awful bosses when they realize they are standing in the way of their happiness.', 'Language': 'English', 'Country': 'USA', 'Awards': '3 wins & 11 nominations.', 'Poster': 'https://images-na.ssl-images-amazon.com/images/M/MV5BNzYxNDI5Njc5NF5BMl5BanBnXkFtZTcwMDUxODE1NQ@@._V1_SX300.jpg', 'Ratings': [{'Source': 'Internet Movie Database', 'Value': '6.9/10'}, {'Source': 'Rotten Tomatoes', 'Value': '69%'}, {'Source': 'Metacritic', 'Value': '57/100'}], 'Metascore': '57', 'imdbRating': '6.9', 'imdbVotes': '378,076', 'imdbID': 'tt1499658', 'Type': 'movie', 'DVD': '11 Oct 2011', 'BoxOffice': '$116,900,000', 'Production': 'Warner Bros. Pictures', 'Website': 'http://horriblebossesmovie.warnerbros.com/index.html', 'Response': 'True'}
{'Title': 'The Terminator', 'Year': '1984', 'Rated': 'R', 'Released': '26 Oct 1984', 'Runtime': '107 min', 'Genre': 'Action, Sci-Fi', 'Director': 'James Cameron', 'Writer': 'James Cameron, Gale Anne Hurd, William Wisher (additional dialogue)', 'Actors': 'Arnold Schwarzenegger, Michael Biehn, Linda Hamilton, Paul Winfield', 'Plot': 'A seemingly indestructible humanoid cyborg is sent from 2029 to 1984 to assassinate a waitress, whose unborn son will lead humanity in a war against the machines, while a soldier from that war is sent to protect her at all costs.', 'Language': 'English, Spanish', 'Country': 'UK, USA', 'Awards': '6 wins & 6 nominations.', 'Poster': 'https://images-na.ssl-images-amazon.com/images/M/MV5BODE1MDczNTUxOV5BMl5BanBnXkFtZTcwMTA0NDQyNA@@._V1_SX300.jpg', 'Ratings': [{'Source': 'Internet Movie Database', 'Value': '8.0/10'}, {'Source': 'Rotten Tomatoes', 'Value': '100%'}, {'Source': 'Metacritic', 'Value': '83/100'}], 'Metascore': '83', 'imdbRating': '8.0', 'imdbVotes': '665,460', 'imdbID': 'tt0088247', 'Type': 'movie', 'DVD': '03 Sep 1997', 'BoxOffice': 'N/A', 'Production': 'Orion Pictures Corporation', 'Website': 'http://www.terminator1.com/', 'Response': 'True'}
Title Year Rated Runtime Genre
0 Blade Runner 2049 2017 R 164 min Mystery, Sci-Fi, Thriller
1 Fight Club 1999 R 139 min Drama
2 Glengarry Glen Ross 1992 R 100 min Crime, Drama, Mystery
3 Horrible Bosses 2011 R 98 min Comedy, Crime
4 The Terminator 1984 R 107 min Action, Sci-Fi
groupby
does nothing here,
because each group is of size 1.
For example, the combination
"Porto", "Portugal"
occurs in only
one
row.
Don’t print an empty first line:
Council Members Adams Adrienne Maisel Alan Ampry-Samuel Alicka Cohen Andrew King Andy etc.
No need to
score
each line twice
(lines
29
and
33).
Either print the names with the last name last,
import sys
import pandas as pd
url = "https://data.cityofnewyork.us/api/views/uvw5-9znb/rows.csv"
try:
df = pd.read_csv(url)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
# Create list from df
nameList = df['NAME'].tolist()
def score(name):
"""
Return the name with the last name moved to the front.
For example, "Lyndon B. Johnson" becomes "Johnson Lyndon B.".
"""
t = name.rpartition(" ") #t is a tuple containing 3 strings.
return f"{t[2]} {t[0]}"
print("Council Members:")
print(*sorted(nameList, key = score), sep = "\n")
sys.exit(0)
Council Members: Adrienne Adams Alicka Ampry-Samuel Diana Ayala Inez Barron Joseph Borelli etc.or print the names with the last name first, followed by a comma:
import sys
import pandas as pd
url = "https://data.cityofnewyork.us/api/views/uvw5-9znb/rows.csv"
try:
df = pd.read_csv(url)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
def score(name):
"""
Return the name with the last name moved to the front.
For example, "Lyndon B. Johnson" becomes "Johnson Lyndon B.".
"""
t = name.rpartition(" ") #t is a tuple containing 3 strings.
return f"{t[2]}, {t[0]}"
# Create list from df
nameList = df['NAME'].tolist()
nameList = [score(name) for name in nameList]
print("Council Members:")
print(*sorted(nameList), sep = "\n")
sys.exit(0)
Council Members: Adams, Adrienne Ampry-Samuel, Alicka Ayala, Diana Barron, Inez Borelli, Joseph etc.Do all the work in pandas:
"""
Read list of names and sort by last name.
"""
import sys
import pandas as pd
url = "https://data.cityofnewyork.us/api/views/uvw5-9znb/rows.csv"
try:
df = pd.read_csv(url)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
#Remove every column except the "NAME" column.
df = df[["NAME"]]
def score(name):
"""
Return the name with the last name moved to the front.
For example, "Lyndon B. Johnson" becomes "Johnson Lyndon B.".
"""
t = name.rpartition(" ") #t is a tuple containing 3 strings.
return f"{t[2]} {t[0]}"
#Temporarily add a column named "score". Delete the column when no longer needed.
df["score"] = df["NAME"].apply(score)
df.sort_values(by = "score", inplace = True)
del df["score"]
s = df.to_string(header = False, index = False)
print(s)
sys.exit(0)
How to left-justify?
Adrienne Adams
Alicka Ampry-Samuel
Diana Ayala
Inez Barron
Joseph Borelli
The XML data is shaped like a family tree. Unfortunately, American Psycho is classified as a 1990s thriller even though it was released in 2000.
The code in lines 20–21 does not pretty print the XML. The downloaded XML was printed prettily because the file of XML in line 10 just happened to be typed prettily. To pretty print, see lines 47–56 in XML.
<?xml version='1.0' encoding='utf8'?>
<collection>
<genre category="Action">
<decade years="1980s">
<movie favorite="True" title="Indiana Jones: The raiders of the lost Ark">
<format multiple="No">DVD</format>
<year>1981</year>
<rating>PG</rating>
<description>
'Archaeologist and adventurer Indiana Jones
is hired by the U.S. government to find the Ark of the
Covenant before the Nazis.'
</description>
</movie>
<movie favorite="True" title="THE KARATE KID">
<format multiple="Yes">DVD,Online</format>
<year>1984</year>
<rating>PG</rating>
<description>None provided.</description>
</movie>
<movie favorite="False" title="Back 2 the Future">
<format multiple="False">Blu-ray</format>
<year>1985</year>
<rating>PG</rating>
<description>Marty McFly</description>
</movie>
</decade>
<decade years="1990s">
<movie favorite="False" title="X-Men">
<format multiple="Yes">dvd, digital</format>
<year>2000</year>
<rating>PG-13</rating>
<description>Two mutants come to a private academy for their kind whose resident superhero team must
oppose a terrorist organization with similar powers.</description>
</movie>
<movie favorite="True" title="Batman Returns">
<format multiple="No">VHS</format>
<year>1992</year>
<rating>PG13</rating>
<description>NA.</description>
</movie>
<movie favorite="False" title="Reservoir Dogs">
<format multiple="No">Online</format>
<year>1992</year>
<rating>R</rating>
<description>WhAtEvER I Want!!!?!</description>
</movie>
</decade>
</genre>
<genre category="Thriller">
<decade years="1970s">
<movie favorite="False" title="ALIEN">
<format multiple="Yes">DVD</format>
<year>1979</year>
<rating>R</rating>
<description>"""""""""</description>
</movie>
</decade>
<decade years="1980s">
<movie favorite="True" title="Ferris Bueller's Day Off">
<format multiple="No">DVD</format>
<year>1986</year>
<rating>PG13</rating>
<description>Funny movie about a funny guy</description>
</movie>
<movie favorite="FALSE" title="American Psycho">
<format multiple="No">blue-ray</format>
<year>2000</year>
<rating>Unrated</rating>
<description>psychopathic Bateman</description>
</movie>
</decade>
</genre>
</collection>
Movies Released in Year 2000
{'favorite': 'False', 'title': 'X-Men'}
{'favorite': 'FALSE', 'title': 'American Psycho'}
"""
Read XML and return movies released in a given year.
Created: 2019-10-16
"""
import sys
import requests
import xml.etree.ElementTree as ET
url = 'https://raw.githubusercontent.com/SF19PB1-k1chan/hw19/master/movies.xml'
try:
response = requests.get(url)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
#decode sequence of bytes into a string
try:
s = response.content.decode(encoding = "utf-8")
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
try:
tree = ET.fromstring(s)
except ET.ParseError as error:
print(error, file = sys.stderr)
sys.exit(1)
year = 2000 #or try 1979, 1981, 1984, 1985, 1986
print(f"Movies Released in Year {year}")
print()
for movie in tree.findall(f"genre/decade/movie/[year='{year}']"):
print(70 * "-")
title = movie.attrib["title"]
#Sort the attributes alphabetically, but with the title first.
for attribute in sorted(movie.attrib,
key = lambda attribute: "AAAAA" if attribute == "title" else attribute):
print(f'{attribute + ":":12} {movie.attrib[attribute]}')
for child in movie:
print(f'{child.tag + ":":12} {child.text}')
genre = tree.find(f"genre/decade/movie/[@title='{title}']../..") #Go up 2 levels.
print(f'{"category:":12} {genre.attrib["category"]}')
print()
sys.exit(0)
Movies Released in Year 2000 ---------------------------------------------------------------------- title: X-Men favorite: False
The XML data is shaped like a family tree. Unfortunately, American Psycho is classified as a 1990s thriller even though it was released in 2000.
The code in lines 20–21 does not pretty print the XML. The downloaded XML was printed prettily because the file of XML in line 10 just happened to be typed prettily. To pretty print, see lines 47–56 in XML.
<?xml version='1.0' encoding='utf8'?>
<collection>
<genre category="Action">
<decade years="1980s">
<movie favorite="True" title="Indiana Jones: The raiders of the lost Ark">
<format multiple="No">DVD</format>
<year>1981</year>
<rating>PG</rating>
<description>
'Archaeologist and adventurer Indiana Jones
is hired by the U.S. government to find the Ark of the
Covenant before the Nazis.'
</description>
</movie>
<movie favorite="True" title="THE KARATE KID">
<format multiple="Yes">DVD,Online</format>
<year>1984</year>
<rating>PG</rating>
<description>None provided.</description>
</movie>
<movie favorite="False" title="Back 2 the Future">
<format multiple="False">Blu-ray</format>
<year>1985</year>
<rating>PG</rating>
<description>Marty McFly</description>
</movie>
</decade>
<decade years="1990s">
<movie favorite="False" title="X-Men">
<format multiple="Yes">dvd, digital</format>
<year>2000</year>
<rating>PG-13</rating>
<description>Two mutants come to a private academy for their kind whose resident superhero team must
oppose a terrorist organization with similar powers.</description>
</movie>
<movie favorite="True" title="Batman Returns">
<format multiple="No">VHS</format>
<year>1992</year>
<rating>PG13</rating>
<description>NA.</description>
</movie>
<movie favorite="False" title="Reservoir Dogs">
<format multiple="No">Online</format>
<year>1992</year>
<rating>R</rating>
<description>WhAtEvER I Want!!!?!</description>
</movie>
</decade>
</genre>
<genre category="Thriller">
<decade years="1970s">
<movie favorite="False" title="ALIEN">
<format multiple="Yes">DVD</format>
<year>1979</year>
<rating>R</rating>
<description>"""""""""</description>
</movie>
</decade>
<decade years="1980s">
<movie favorite="True" title="Ferris Bueller's Day Off">
<format multiple="No">DVD</format>
<year>1986</year>
<rating>PG13</rating>
<description>Funny movie about a funny guy</description>
</movie>
<movie favorite="FALSE" title="American Psycho">
<format multiple="No">blue-ray</format>
<year>2000</year>
<rating>Unrated</rating>
<description>psychopathic Bateman</description>
</movie>
</decade>
</genre>
</collection>
Movies Released in Year 2000
{'favorite': 'False', 'title': 'X-Men'}
{'favorite': 'FALSE', 'title': 'American Psycho'}
"""
Read XML and return movies released in a given year.
Created: 2019-10-16
"""
import sys
import requests
import xml.etree.ElementTree as ET
url = 'https://raw.githubusercontent.com/SF19PB1-k1chan/hw19/master/movies.xml'
try:
response = requests.get(url)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
#decode sequence of bytes into a string
try:
s = response.content.decode(encoding = "utf-8")
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
try:
tree = ET.fromstring(s)
except ET.ParseError as error:
print(error, file = sys.stderr)
sys.exit(1)
year = 2000 #or try 1979, 1981, 1984, 1985, 1986
print(f"Movies Released in Year {year}")
print()
for movie in tree.findall(f"genre/decade/movie/[year='{year}']"):
print(70 * "-")
title = movie.attrib["title"]
#Sort the attributes alphabetically, but with the title first.
for attribute in sorted(movie.attrib,
key = lambda attribute: "AAAAA" if attribute == "title" else attribute):
print(f'{attribute + ":":12} {movie.attrib[attribute]}')
for child in movie:
print(f'{child.tag + ":":12} {child.text}')
genre = tree.find(f"genre/decade/movie/[@title='{title}']../..") #Go up 2 levels.
print(f'{"category:":12} {genre.attrib["category"]}')
print()
sys.exit(0)
Movies Released in Year 2000
----------------------------------------------------------------------
title: X-Men
favorite: False
format: dvd, digital
year: 2000
rating: PG-13
description: Two mutants come to a private academy for their kind whose resident superhero team must
oppose a terrorist organization with similar powers.
category: Action
----------------------------------------------------------------------
title: American Psycho
favorite: FALSE
format: blue-ray
year: 2000
rating: Unrated
description: psychopathic Bateman
category: Thriller
Imitate the pandas code in
defaultdict.py.
df["Borough"]
is a pandas
Series.
So are
df["Borough"].value_counts()
and
df["Borough"].value_counts().sort_index().
"""
Print number of dog bites in each borough.
https://data.cityofnewyork.us/Health/DOHMH-Dog-Bite-Data/rsgh-akpg
"""
import sys
import pandas as pd
url = "https://data.cityofnewyork.us/api/views/rsgh-akpg/rows.csv"
try:
df = pd.read_csv(url) #df is a pandas DataFrame.
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
series = df["Borough"].value_counts().sort_index() #alphabetical order
print(series)
sys.exit(0)
Bronx 1757 Brooklyn 2281 Manhattan 2354 Other 437 Queens 2520 Staten Island 931 Name: Borough, dtype: int64
Try to damage the URL in these three ways:
CAR_DATA = 'xhttps://bit.ly/2Ov65SJ' CAR_DATA = 'https://xbit.ly/2Ov65SJ' CAR_DATA = 'https://bit.ly/x2Ov65SJ'
The
docstring
says that the function
most_prolific_automaker
returns a
string,
but the function actually returns
None.
"""
Print the name of the most prolific automaker for a given year, if any.
"""
import sys
import requests
from collections import Counter
CAR_DATA = 'https://bit.ly/2Ov65SJ'
with requests.Session() as session: #will close the session when done with it
try:
response = session.get(CAR_DATA)
except BaseException as error:
print("get", type(error), error, file = sys.stderr)
sys.exit(1)
try:
response.raise_for_status()
except BaseException as error:
print("status", type(error), error, file = sys.stderr)
sys.exit(1)
try:
data = response.json() #data should be a big list of 1000 dictionaries
except BaseException as error:
print("json", type(error), error, file = sys.stderr)
sys.exit(1)
assert isinstance(data, list)
def most_prolific_automaker(year):
"""Given int year, return name of automaker that released
the highest number of new car models. If none, raise an exception."""
automakers = [item['automaker'] for item in data if item['year'] == year]
#print(automakers)
counter = Counter(automakers)
listOfTuples = counter.most_common(1)
try:
firstTuple = listOfTuples[0]
except IndexError:
raise ValueError(f"Sorry, no automakers for the year {year}.")
name, count = firstTuple
return name
year = 2007 #also try 1961
try:
name = most_prolific_automaker(year)
except ValueError as error:
print(error, file = sys.stderr)
sys.exit(1)
print(f"The most prolific automaker of {year} was {name}.")
sys.exit(0)
The most prolific automaker of 2007 was Pontiac.
Sorry, no automakers for the year 1961.
Do the work in pandas.
df
is a pandas
DataFrame;
df[mask]
is a much shorter pandas
DataFrame.
seriesOfStrings
is a pandas
Series;
seriesOfInts
is a much shorter pandas
Series.
"""
Print the name of the most prolific automaker for a given year, if any.
"""
import sys
import pandas as pd
url = 'https://bit.ly/2Ov65SJ'
try:
df = pd.read_json(url) #df is a pandas DataFrame.
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
def most_prolific_automaker(year):
"""Given int year, return name of automaker that released
the highest number of new car models. If none, raise an exception."""
mask = df["year"] == year
seriesOfStrings = df[mask]["automaker"] #index is ints
seriesOfInts = seriesOfStrings.value_counts() #index is strings
try:
return seriesOfInts.index[0] #Get the first string in the index.
except IndexError:
raise ValueError(f"Sorry, no automakers for the year {year}.")
year = 2007 #also try 1961
try:
name = most_prolific_automaker(year)
except ValueError as error:
print(error, file = sys.stderr)
sys.exit(1)
print(f"The most prolific automaker of {year} was {name}.")
sys.exit(0)
Where did the URL
https://data.cityofnewyork.us/resource/wg9x-4ke6.json
come from?
It contains a list of 1000 dictionaries.
Each dictionary contains 41 key/value pairs.
Why are Queens
("QN")
and Staten Island
("SI")
missing?
Lines
18–20
do nothing because the return value of each call to
unique
is discarded.
2019 - 2020 School Type Counts by Borough
nta location_category_description
Brooklyn Early Childhood 3
Elementary 253
High school 166
Junior High-Intermediate-Middle 137
K-12 all grades 23
K-8 80
Secondary School 33
Bronx K-12 all grades 1
Manhattan Early Childhood 1
Elementary 113
High school 47
Junior High-Intermediate-Middle 64
K-12 all grades 15
K-8 42
Secondary School 20
Ungraded 2
dtype: int64
Source:
https://data.cityofnewyork.us/Education/2019-2020-School-Locations/wg9x-4ke6/data
"""
Print the two relevant columns of the pandas DataFrame.
https://data.cityofnewyork.us/Education/2019-2020-School-Locations/wg9x-4ke6
"""
import sys
import pandas as pd
url = "https://data.cityofnewyork.us/resource/wg9x-4ke6.json"
try:
df = pd.read_json(url) #df is a pandas DataFrame.
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
#for i, name in enumerate(df.columns): #Print the name of each column.
# print(i, name)
print(f"len(df) = {len(df)}")
print()
columns = ["nta", "location_category_description"]
s = df[:3].to_string(columns = columns, header = True, index = True) #first 3 rows
print(s)
print()
s = df[-3:].to_string(columns = columns, header = True, index = True) #last 3 rows
print(s)
sys.exit(0)
len(df) = 1000
nta location_category_description
0 BK32 Elementary
1 BK60 Junior High-Intermediate-Middle
2 BK69 Elementary
nta location_category_description
997 MN21 High school
998 MN12 Junior High-Intermediate-Middle
999 MN13 Secondary School
Get the same output without using pandas.
"""
How many schools of each category does each borough have?
https://data.cityofnewyork.us/Education/2019-2020-School-Locations/wg9x-4ke6
"""
import sys
import urllib.request
import json
import collections
url = "https://data.cityofnewyork.us/resource/wg9x-4ke6.json"
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = infile.read() #Read the entire input file.
infile.close()
try:
s = sequenceOfBytes.decode("utf-8") #s is a string.
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
try:
bigList = json.loads(s) #bigList is a list of dictionaries.
except json.JSONDecodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
#Each key will be a two-character string; each value will be a collections.Counter.
d = collections.defaultdict(collections.Counter)
for school in bigList: #Each school is a dictionary containing 41 key/value pairs.
borough = school["nta"][:2]
category = school["location_category_description"]
d[borough][category] += 1
newNames = {
"BK": "Brooklyn",
"BX": "Bronx",
"MN": "Manhattan",
"QN": "Queens",
"SI": "Staten Island" #13 characters; n = len(max(newNames.values(), key = len))
}
#Dictionary comprehension: rename the keys.
d = {newNames[key]: value for key, value in d.items()}
for borough in sorted(d): #boroughs in alphabetical order
print(f"{borough:13}", end = "")
counter = d[borough]
for i, category in enumerate(sorted(counter)): #categories in alphabetical order
indent = 13 * " " if i > 0 else ""
print(f"{indent}{counter[category]:4} {category}")
print()
total = sum([n for counter in d.values() for n in counter.values()])
print(f'{"total":13}{total:4}')
sys.exit(0)
Bronx 1 K-12 all grades
Brooklyn 3 Early Childhood
253 Elementary
166 High school
137 Junior High-Intermediate-Middle
23 K-12 all grades
80 K-8
33 Secondary School
Manhattan 1 Early Childhood
113 Elementary
47 High school
64 Junior High-Intermediate-Middle
15 K-12 all grades
42 K-8
20 Secondary School
2 Ungraded
total 1000
The
for
loop in
lines
25–28
will iterate through the verses in the correct order only in versions 3.7 and
newer of Python.
To get the correct order in every version,
use a
list
or a
tuple
instead of the
dictionary
in
lines
12–21.
And now that we have a
list
or
tuple,
we can add a second column as in
Old MacDonald.
Append each verse to
s
using the
+=
operator.
"""
bus.py
Demonstrate a tuple of tuples to output song lyrics and then speak them.
"""
import sys
import tempfile
import playsound
import gtts #Google Text-To-Speech
verses = ( #verses is a tuple containing 8 tuples
("wheels", "round and round"),
("wipers", "swish swish swish"),
("horn", "beep beep beep"),
("doors", "open and shut"),
("driver", "move on back"),
("babies", "wah wah wah"),
("mommies", "shush shush shush"),
("muggers", "bang bang bang")
)
f = """\
The {} on the bus {} {},
{}, {}.
The {} on the bus {} {},
All through the town.
"""
song = ""
for verse in verses: #Each verse is a tuple containing 2 strings.
noun = verse[0]
verb = verse[1]
go = "go" if noun.endswith("s") else "goes" #plural vs. singular
song += f.format(noun, go, verb, verb.capitalize(), verb, noun, go, verb)
print(song, end = "")
try:
textToSpeech = gtts.gTTS(text = song, lang = "en-us", slow = False)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
# Save the audio in a temporary file with a name.
temporaryFile = tempfile.NamedTemporaryFile()
textToSpeech.save(temporaryFile.name)
# Play and erase the temporary file.
try:
playsound.playsound(temporaryFile.name, True) #Requires a filename or URL.
except OSError as error:
print(error, file = sys.stderr)
sys.exit(1)
finally:
temporaryFile.close() #Erase the temporary file.
sys.exit(0)
Here’s a simpler to create
noun
and
verb,
combined with another way to create each verse.
You can see which expression goes into which pocket,
but it’s harder to see that the body of the
for
loop is indented.
song = ""
for noun, verb in verses: #Each verse is a tuple containing 2 strings.
go = "go" if noun.endswith("s") else "goes" #plural vs. singular
song += f"""\
The {noun} on the bus {go} {verb},
{verb.capitalize()}, {verb}.
The {noun} on the bus {go} {verb},
All through the town.
"""
The wheels on the bus go round and round, Round and round, round and round. The wheels on the bus go round and round, All through the town. The wipers on the bus go swish swish swish, Swish swish swish, swish swish swish. The wipers on the bus go swish swish swish, All through the town. The horn on the bus goes beep beep beep, Beep beep beep, beep beep beep. The horn on the bus goes beep beep beep, All through the town. The doors on the bus go open and shut, Open and shut, open and shut. The doors on the bus go open and shut, All through the town. The driver on the bus goes move on back, Move on back, move on back. The driver on the bus goes move on back, All through the town. The babies on the bus go wah wah wah, Wah wah wah, wah wah wah. The babies on the bus go wah wah wah, All through the town. The mommies on the bus go shush shush shush, Shush shush shush, shush shush shush. The mommies on the bus go shush shush shush, All through the town. The muggers on the bus go bang bang bang, Bang bang bang, bang bang bang. The muggers on the bus go bang bang bang, All through the town.
The file you feed into a
csv.reader
must be a CSV file,
not a JSON file.
"""
Dog_bites.py
Reported number of dog bites in each borough of NYC from 2015 to 2017.
"""
import sys
import urllib.request
import csv
import collections
#https://data.cityofnewyork.us/Health/DOHMH-Dog-Bite-Data/rsgh-akpg
url = "https://data.cityofnewyork.us/api/views/rsgh-akpg/rows.csv"
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
readbytes = infile.read() #Read whole file into one big sequence of bytes.
infile.close()
try:
s = readbytes.decode("utf-8")
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
lines = csv.reader(s.splitlines()[1:]) #Skip the first line.
#list of names of boroughs
listOfStrings = [line[7] for line in lines if "DOG" in line[2]]
counter = collections.Counter(listOfStrings)
print("Number of dog bites in each borough from 2015-2017:")
print()
#Alphabetical order, except that "Other" comes last.
for borough in sorted(counter, key = lambda borough: "ZZZZZ" if borough == "Other" else borough):
print(f"{counter[borough]:5,} {borough}")
sys.exit(0)
Output is alphabetical, except that “Other” comes last.
Number of dog bites in each borough from 2015-2017: 1,757 Bronx 2,281 Brooklyn 2,354 Manhattan 2,520 Queens 931 Staten Island 437 Other
If all you want to do is count,
it’s simpler to use a
collections.Counter
instead of a
collections.defaultdict.
Instead of changing
"M"
to
"Manhattan"
413 times,
change it only once.
"""
Use a collections.Counter to count the crimes by borough.
Created: 2019-10-09
Dataset: https://data.cityofnewyork.us/Education/2017-2018-Schools-NYPD-Crime-Data-Report/kwvk-z7i9/data
"""
import sys
import collections
import pandas as pd
url = "https://data.cityofnewyork.us/api/views/kwvk-z7i9/rows.csv"
try:
df = pd.read_csv(url) #df is a pandas DataFrame.
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
#d is a dictionary containing 5 keys and 5 values.
#Each key is a one-character string, and each value is an int.
d = collections.Counter(df["Borough"])
newNames = {
"K": "Brooklyn",
"M": "Manhattan",
"Q": "Queens",
"R": "Staten Island",
"X": "Bronx"
}
#Dictionary comprehension: the new dictionary newd has the same content as d,
#except that each key is a name instead of just an initial.
newd = {newNames[key]: value for key, value in d.items()}
print("""\
2017 - 2018 Schools NYPD Crime Data Report
Source:
https://data.cityofnewyork.us/Education/2017-2018-Schools-NYPD-Crime-Data-Report/kwvk-z7i9/data
Counts by Borough
""")
for boro in sorted(newd): #alphabetical order
print(f"{newd[boro]:3} {boro}")
sys.exit(0)
2017 - 2018 Schools NYPD Crime Data Report Source: https://data.cityofnewyork.us/Education/2017-2018-Schools-NYPD-Crime-Data-Report/kwvk-z7i9/data Counts by Borough 455 Bronx 621 Brooklyn 413 Manhattan 348 Queens 82 Staten Island
Do all the work in pandas:
"""
Use a collections.Counter to count the crimes by borough.
Created: 2019-10-09
Dataset: https://data.cityofnewyork.us/Education/2017-2018-Schools-NYPD-Crime-Data-Report/kwvk-z7i9/data
"""
import sys
import collections
import pandas as pd
url = "https://data.cityofnewyork.us/api/views/kwvk-z7i9/rows.csv"
try:
df = pd.read_csv(url) #df is a pandas DataFrame.
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
newNames = {
"K": "Brooklyn",
"M": "Manhattan",
"Q": "Queens",
"R": "Staten Island",
"X": "Bronx"
}
print(df["Borough"].value_counts().rename(newNames).sort_index())
print()
print("df = (showing only the first 5 rows)")
print(df[:5])
print()
print('df["Borough"] = (showing only the first 5 rows)')
print(df["Borough"][:5]) #df["Borough"] is a pandas Series
print()
print('df["Borough"].value_counts() = ')
print(df["Borough"].value_counts())
print()
print('df["Borough"].value_counts().rename(newNames) = ')
print(df["Borough"].value_counts().rename(newNames))
print()
print('df["Borough"].value_counts().rename(newNames).sort_index() = ')
print(df["Borough"].value_counts().rename(newNames).sort_index())
print()
print("Print with a Python for loop:")
for key, value in dict(df["Borough"].value_counts().rename(newNames).sort_index()).items():
print(f"{value:3} {key}")
sys.exit(0)
Bronx 455
Brooklyn 621
Manhattan 413
Queens 348
Staten Island 82
Name: Borough, dtype: int64
df = (showing only the first 5 rows)
ID Building Code ... City Council Districts Police Precincts
0 288 K247 ... NaN NaN
1 335 K281 ... NaN NaN
2 359 K298 ... 37.0 46.0
3 390 K318 ... NaN NaN
4 400 K327 ... NaN NaN
[5 rows x 30 columns]
df["Borough"] = (showing only the first 5 rows)
0 K
1 K
2 K
3 K
4 K
Name: Borough, dtype: object
df["Borough"].value_counts() =
K 621
X 455
M 413
Q 348
R 82
Name: Borough, dtype: int64
df["Borough"].value_counts().rename(newNames) =
Brooklyn 621
Bronx 455
Manhattan 413
Queens 348
Staten Island 82
Name: Borough, dtype: int64
df["Borough"].value_counts().rename(newNames).sort_index() =
Bronx 455
Brooklyn 621
Manhattan 413
Queens 348
Staten Island 82
Name: Borough, dtype: int64
Print with a Python for loop:
455 Bronx
621 Brooklyn
413 Manhattan
348 Queens
82 Staten Island
Can create the
dictionary
with the
dictionary
comprehension
we saw
here.
Code after
root.mainloop()
is never executed.
"""
Create dictionary from European countries and capitals csv.
Created: 2019-10-07
"""
import sys
import urllib.request
import csv
import tkinter as tk
from tkinter import ttk
url = "https://raw.githubusercontent.com/SF19PB1-k1chan/hw16/master/euro_capitals.csv"
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = infile.read() #Read whole file into one big sequenceOfBytes.
infile.close()
try:
s = sequenceOfBytes.decode("utf-8") #s is a string
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
#Dictionary comprehension. line[0] is the country, line[1] is the capital.
euroDict = {line[0]: line[1] for line in csv.reader(s.splitlines())}
root = tk.Tk()
root.title("European Capitals")
instructions = tk.Label(root, text = "Select country:", anchor = "w", padx = 5)
instructions.grid(row = 0, column = 0)
countryName = tk.StringVar()
capitalName = ttk.Combobox(
root,
values = sorted(euroDict),
justify = "center",
textvariable = countryName
)
capitalName.bind(
'<<ComboboxSelected>>',
lambda event: answer.config(text =
f"The capital of {countryName.get()} is {euroDict[countryName.get()]}.")
)
capitalName.current(0)
capitalName.grid(row = 0, column = 1)
answer = tk.Label(root, anchor = "w", padx = 5)
answer.grid(row = 1, column = 0, columnspan = 2, sticky = "ew")
root.mainloop()
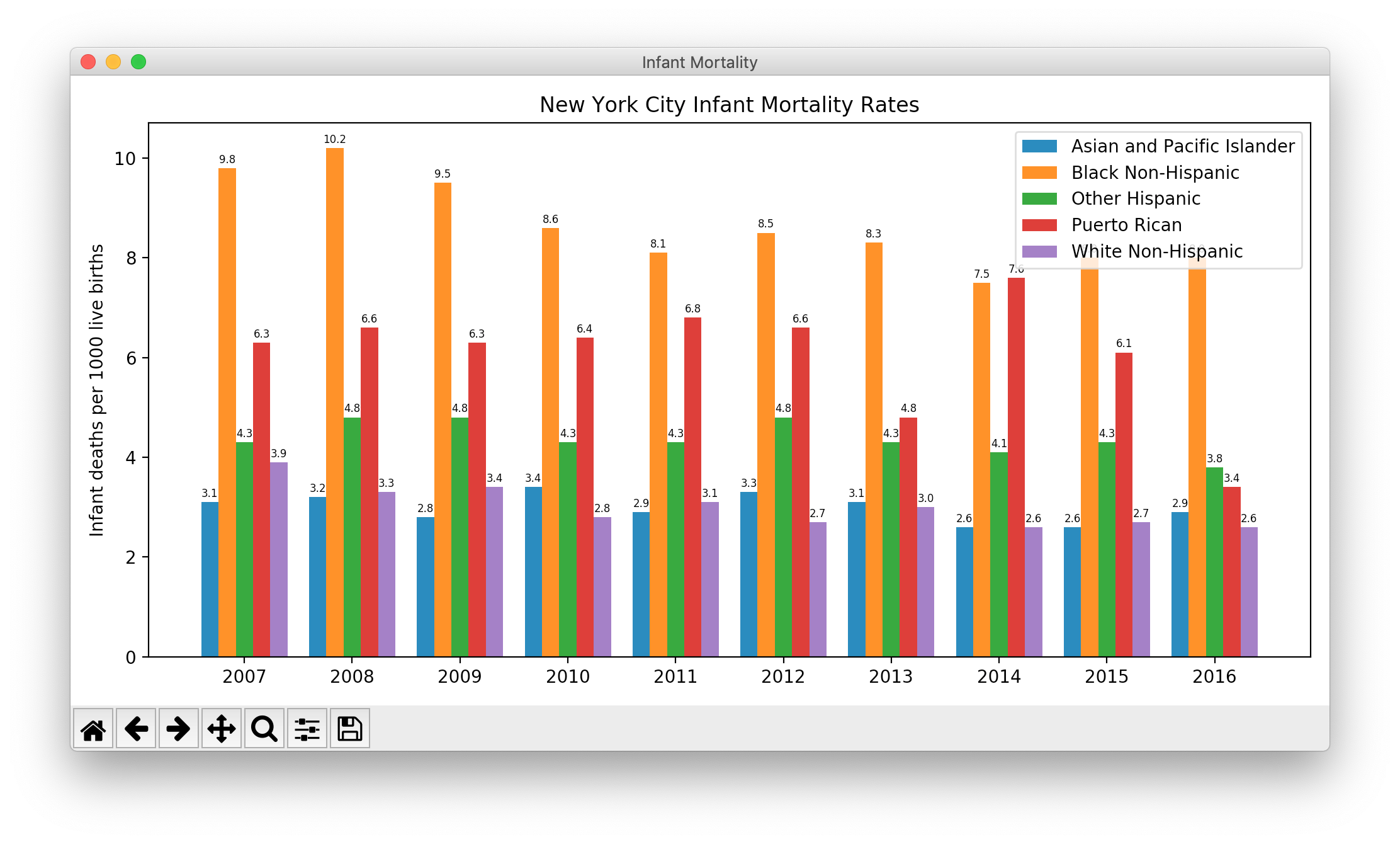
Before attempting a grouped bar chart, make sure you can create a single bar chart.
"""
infantmortality.py
NYC infant mortality rate from 2007-2016 from
https://data.cityofnewyork.us/Health/Infant-Mortality/fcau-jc6k
Barchart modeled after
https://matplotlib.org/gallery/lines_bars_and_markers/barchart.html
"""
import sys
import urllib.request
import csv
import matplotlib.pyplot as plt
import numpy as np
import collections
url = "https://raw.githubusercontent.com/jhjhjhsu/InfantMortality/master/InfantMortality.csv"
#access data
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = infile.read() #Read whole file into one big sequenceOfBytes.
infile.close()
try:
s = sequenceOfBytes.decode("utf-8") #s is a string
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
#The keys in this dictionary will be years.
#The default value for each key will be an empty dictionary created by the dict function.
#The keys in the empty dictionary will eventually be races.
#The values in the empty dictionary will eventually be rates.
d = collections.defaultdict(dict)
#[1:] because the first line in the CSV file is a line of titles.
for line in csv.reader(s.splitlines()[1:]): #Each line is a list of 9 strings.
try:
rate = float(line[2])
except ValueError as error:
continue #Skip this line if it has no rate.
year = int(line[0])
race = line[1]
d[year][race] = rate #d[year] is a little dictionary
figure, axes = plt.subplots(figsize = (10, 5)) #inches
figure.canvas.set_window_title("Infant Mortality")
axes.set_title("New York City Infant Mortality Rates")
axes.set_ylabel("Infant deaths per 1000 live births")
years = sorted(d) #years is a list of the keys of d in increasing numeric order
x = np.arange(len(years)) #the label locations
axes.set_xticks(x)
axes.set_xticklabels(years)
#Set comprehension. Each value is a little dictionary, each race is a string.
#races is a list of strings (no duplicates) in alphabetical order.
races = sorted({race for value in d.values() for race in value})
n = len(races)
width = .8 / n #the width of each bar
for i, race in enumerate(races):
rates = [d[year][race] for year in years] #rates is a list of floats
barContainer = axes.bar(
x + (i - n / 2) * width,
rates,
width,
align = "edge",
label = race
)
#Print a number on top of each bar belonging to this race.
for bar in barContainer:
height = bar.get_height()
axes.annotate(
height, #the number to be printed
xy = (bar.get_x() + bar.get_width() / 2, height),
xytext = (0, 1.5), #1.5 points vertical offset
textcoords = "offset points",
ha = "center",
va = "bottom",
size = 6
)
axes.legend()
figure.tight_layout()
plt.show()
pip3 install feedparser
Simplify lines 25–28
if len(url.split('>')) <= 1:
continue
else:
game_list.append(Game((url.split('>')[1]), url[6:47]))
to
if len(url.split('>')) > 1:
game_list.append(Game(url.split('>')[1], url[6:47]))
Self-documenting:
if len(url.split('>')) > 1:
title = url.split('>')[1]
link = url[6:47]
game = Game(title, link)
game_list.append(game)
Give
get_games
an argument and a return value.
Build the
game_list
with a
list
comprehension?
Easier and safer to parse the link with a
regular expression
or with
Beautiful Soup
instead of with three calls to
index.
"""
Take items from a given URL
and return the title and URL of each item as a namedtuple of type Game.
"""
import sys
from collections import namedtuple
import feedparser
def get_games(url):
"""Parse Steam's RSS feed and return a list of Game namedtuples."""
content = feedparser.parse(url)
if content.bozo != 0:
print(type(content.bozo_exception), content.bozo_exception, file = sys.stderr)
sys.exit(1)
game_list = []
for entry in content.entries:
summary = entry.summary
try:
i = summary.index("<a href='") #Look for a 9-character substring.
j = summary.index("'>")
k = summary.index("</a>")
except ValueError: #A call to index didn't find what it was looking for.
continue #Go on to the next entry.
if 0 == i < j < k:
title = summary[j+2:k]
link = summary[9:j]
game = Game(title, link)
game_list.append(game)
return game_list
Game = namedtuple("Game", ["title", "link"]) #Create a new type of tuple containing 2 items.
# cached version to have predictable results for testing
FEED_URL = "http://bit.ly/2IkFe9B"
for game in get_games(FEED_URL):
print(f"{game.link} {game.title}")
sys.exit(0)
http://store.steampowered.com/app/535520/ Nidhogg 2 http://store.steampowered.com/app/467660/ Paranormal Activity: The Lost Soul http://store.steampowered.com/app/514900/ >observer_ http://store.steampowered.com/app/304530/ Agents of Mayhem http://store.steampowered.com/app/597220/ West of Loathing http://store.steampowered.com/app/495050/ Mega Man Legacy Collection 2 http://store.steampowered.com/app/606730/ Sine Mora EX http://store.steampowered.com/app/675260/ Batman: The Enemy Within - The Telltale Series http://store.steampowered.com/app/414340/ Hellblade: Senua's Sacrifice http://store.steampowered.com/app/350280/ LawBreakers http://store.steampowered.com/app/501320/ The Shrouded Isle http://store.steampowered.com/app/573170/ Fidel Dungeon Rescue http://store.steampowered.com/app/553880/ Archangel http://store.steampowered.com/app/343860/ Tacoma http://store.steampowered.com/app/404680/ Hob http://store.steampowered.com/app/433340/ Slime Rancher http://store.steampowered.com/app/447290/ Redeemer http://store.steampowered.com/app/305620/ The Long Dark http://store.steampowered.com/app/215280/ Secret World Legends http://store.steampowered.com/app/505460/ Foxhole http://store.steampowered.com/app/487120/ Citadel: Forged with Fire http://store.steampowered.com/app/586950/ The Wizards http://store.steampowered.com/app/570420/ X Rebirth VR Edition http://store.steampowered.com/app/535480/ Sundered http://store.steampowered.com/app/645630/ Car Mechanic Simulator 2018 http://store.steampowered.com/app/550650/ Black Squad http://store.steampowered.com/app/671260/ GOKEN http://store.steampowered.com/app/667800/ Loco Dojo
pip3 install easymoney
Please type a Bond Movie (e.g., Skyfall): Skyfall adjusted for inflation grossed: Warning (from warnings module): File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/easymoney/money.py", line 213 warn(warn_msg % (year, natural_region_name, str(fall_back_year))) UserWarning: Inflation (CPI) data for 2019 in 'Canada' could not be obtained from the International Monetary Fund database currently cached. Falling back to 2018. 251,959,737.06 USD
Line 59 asked for Canada because this example asked for Canada. To find the years covered for Canada in the inflation database, I inserted
ep.options(info = "inflation")at line 38 and got this output:
Region Alpha2 Alpha3 Currencies InflationDates Overlap
0 Australia AU AUS AUD [1960, 2018] [04/01/1999, 31/12/2018]
1 Austria AT AUT EUR [1960, 2018] [04/01/1999, 31/12/2018]
2 Belgium BE BEL EUR [1960, 2018] [04/01/1999, 31/12/2018]
3 Brazil BR BRA BRL [1980, 2018] [02/01/2008, 31/12/2018]
4 Bulgaria BG BGR BGN [1985, 2018] [19/07/2000, 31/12/2018]
5 Canada CA CAN CAD [1960, 2018] [04/01/1999, 31/12/2018]
etc.
52 United States US USA USD [1960, 2018] [04/01/1999, 31/12/2018]
etc.
So in line 59,
adjusted_gross = ep.normalize(amount=amount,region="CA", base_currency="USD",from_year=rl, to_year=2019, pretty_print=True)
I changed
"CA"
to
"US"
and
2019
to
2018.
adjusted_gross = ep.normalize(
amount = amount,
region = "US",
base_currency = "USD",
from_year = rl, #release year
to_year = 2018
)
print(f"${adjusted_gross:,.2f}")
Let’s assume the user selected Skyfall. In line 52,
definition
is the 14-character
string
"304360277,2012"{definition}
is a
set
containing that
stringstr({definition})
converts this
set
to the 18-character
string
"{'304360277,2012'}",
containing
{curly
braces} and
'single
quotes'.
string
"{'304360277,2012'}"
is four characters longer than the original
string
"304360277,2012".
Lines
53
and
54
put the
strings
"{'304360277"
and
"304360277"
into
gross.
Lines
54
and
55
put the
strings
"2012'}"
and
"2012"
into
release_yr.
The variables
a,
b,
and
adjusted_gross
(in
line
59)
are never used.
Change lines 52–55 to
gross, release_yr = definition.split(",")
"""
bond.py
Pick a Bond movie and it'll tell you how much it grossed adjusted for inflation.
"""
import sys
from easymoney.money import EasyPeasy
movies = {
"Skyfall": (2012, 304_360_277),
"Spectre": (2015, 200_074_609),
"Quantum of Solace": (2008, 168_368_427),
"Casino Royale": (2006, 167_445_960),
"Die Another Day": (2002, 160_942_139),
"The World Is Not Enough": (1999, 126_943_684),
"Tomorrow Never Dies": (1997, 125_304_276),
"GoldenEye": (1995, 106_429_941),
"Moonraker": (1979, 70_308_099),
"Octopussy": (1983, 67_893_619),
"Thunderball": (1965, 63_595_658),
"Never Say Never Again": (1983, 55_432_841),
"For Your Eyes Only": (1981, 54_812_802),
"The Living Daylights": (1987, 51_185_897),
"Goldfinger": (1964, 51_081_062),
"A View to a Kill": (1985, 50_327_960),
"The Spy Who Loved Me": (1977, 46_838_673),
"Diamonds Are Forever": (1971, 43_819_547),
"You Only Live Twice": (1967, 43_084_787),
"Live and Let Die": (1973, 35_377_836),
"Licence to Kill": (1989, 34_667_015),
"From Russia, with Love": (1964, 24_796_765),
"On Her Majesty's Secret Service": (1969, 22_774_493),
"The Man with the Golden Gun": (1974, 20_972_000),
"Dr. No": (1963, 16_067_035)
}
ep = EasyPeasy()
while True:
try:
movie = input("Please type a Bond Movie (e.g., Skyfall): ")
except EOFError:
sys.exit(0)
try:
release_year, gross = movies[movie] #movies[movie] is a tuple, release_year and gross are ints
except KeyError:
print(f'Sorry, "{movie}" is not a James Bond movie.')
print()
continue #Go back up to the word "while".
adjusted_gross = ep.normalize(
amount = gross,
region = "US",
base_currency = "USD",
from_year = release_year,
to_year = 2018
)
print(f"Adjusted for inflation, grossed ${adjusted_gross:,.2f}")
print()
Please type a Bond Movie (e.g., Skyfall): Skyfall Adjusted for inflation, grossed $332,878,790.78
Line
47
tries to open the file
/content/sample_data/cmt_media.csv,
so I used the CSV file from
plotting9_23.
Change lines 39–43 to
stop_words = set(stopwords.words("english") + ["br", "de", "la"]) #add 2 lists
No need for
line
64
to make a copy of the
list
articles.
In other words, change the
slice
articles[:]
to
articles.
No semicolon in line 63. Consolidate lines 63, 64, 77 to
for article in enumerate(articles, start = 1):
Assuming there are three articles,
lines
62
and
76
put the
set
of three
strings
{"article 1", "article 2", "article 3"}
into the variable
keyed_set.
Lines
61,
74,
75
put a
dictionary
containing six keys into the variable
keyed_articles.
Three of these keys are
ints
(line
74),
three of them are
strings
(line
75):
1, 2, 3, "counts_1", "counts_2", "counts_3"
The
for
loop in
line
90
iterates only at most two times,
because the
slice
listOfTuples[1:4:2]
in that line contains only at most two items.
So we’re examining only the second most frequent word
and the fourth most frequent word in the articles.
Even weirder,
list_of_set_article_numbers
will be a
list
of at most two
sets.
The first of these two sets will contain all three
strings
"article 1", "article 2", "article 3"
The second of these two sets will contain at most three strings
identifying the articles that contain
the fourth most common word in the input.
The
for
loop in
line
92
iterates six times,
because the
dictionary
keyed_articles
contains six items.
But three of these iterations serve no purpose.
The
for
loop needs to iterate only through the keys
1,
2,
3,
not the keys
"counts_1",
"counts_2",
"counts_3".
The
dictionary
keyed_articles
should be replaced by a
list
with two columns:
stats = []
for article in articles:
words = []
for word in article.split():
word = word.strip(punctuation)
if word:
word = word.lower()
if word not in stop_words:
words.append(word)
stats.append((words, collections.Counter(words).most_common())) #append a tuple
The URL in line 10 must be the URL of a CSV file.
Year,New York City Population,NYC Consumption(Million gallons per day),Per Capita(Gallons per person per day) 1979,7102100,1512,213 1980,7071639,1506,213 1981,7089241,1309,185 etc.
Lines
7,
12–15
are never used.
Remove them.
Line
40
is never reached.
Remove it.
Surround the dangerous
line
17
with
try
and
except.
See the bar chart on
September 17.
"""
Read water consumption rates from URL and display bar chart.
https://data.cityofnewyork.us/Environment/Water-Consumption-In-The-New-York-City/ia2d-e54m/data
"""
import matplotlib.pyplot as plt
import pandas as pd
import sys
url = "https://data.cityofnewyork.us/api/views/ia2d-e54m/rows.csv"
try:
df = pd.read_csv(url, index_col = 0)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
figure, ax0 = plt.subplots(figsize = (10, 6))
ax1 = ax0.twinx()
ax2 = ax0.twinx()
figure.canvas.set_window_title("Water Consumption")
plt.title("NYC Water Consumption Rates")
fields = [
[2, ax0, "crimson", "Population", "New York City Population"],
[1, ax1, "navy", "Water Consumption", "NYC Consumption(Million gallons per day)"],
[0, ax2, "green", "Per Capita", "Per Capita(Gallons per person per day)"]
]
for field in fields:
ax = field[1]
color = field[2]
series = df[field[4]] #series is a pandas Series object. See Series.
series.plot(
kind = "bar",
color = color,
ax = ax,
width = .25,
position = field[0] - .5
)
ax.set_ylabel(field[3], color = color)
ax.tick_params(axis = "y", labelcolor = color)
plt.ticklabel_format(style = "plain", axis = "y")
plt.show()
The 1979 population got cut off. How to fix? Print the population with commas (8,000,000)?
Change line 21 from
[b[0][0],b[1][0],b[2][0]], #left columnto
[b[i][0] for i in range(3)], #left columnAre the comments in lines 26–27 wrong? Change line 31 from
if strikes == ["O", "O", "O"]:to
if strikes == 3 * ["O"]:
Create a new variable
n = 3and change all the other
3s
to
n.
Indent with groups of four spaces, not tabs. Simplify line 15 (and line 21) from
for x in range(0,3):
to
for x in range(3):
Simplify line 16 from
row = set([grid[x][0],grid[x][1],grid[x][2]])
to
row = set(grid[x]) #grid[x] is a list of 3 strings.
Simplify line 22 from
column = set([grid[0][x],grid[1][x],grid[2][x]])
to the
list
comprehension
column = set([grid[i][x] for i in range(3)])
Simplify line 27 from
diag1 = set([grid[0][0],grid[1][1],grid[2][2]])
to
diag1 = set([grid[i][i] for i in range(3)])
Can you simplify the other diaginal
line
28?
Create a new variable
n = 3and change all the other
3s
to
n.
checkGrid
finds only at most one winner.
If there is no winner, it should probably return
" "
or
None.
When we stored the playing board in a
string
of nine characters in
Tic,
we found all the winner with only one statement of code.
"""
Check tic-tac-toe board for winner(s).
"""
import sys
import numpy as np
testGrid = [
['X', 'X', ' '],
['X', 'O', ' '],
['X', ' ', 'O']
]
n = len(testGrid) #number of rows must be equal to number of columns
b = np.array(testGrid) #b is a two-dimensional numpy.ndarray
#print(b.shape) #prints the tuple (3, 3)
def checkGrid(grid):
"Return a string of the winning characters."
winners = ""
for c in "XO":
trio = n * [c] #trio is a list of 3 strings
# rows
for row in range(n):
if np.array_equal(b[row, 0:n], trio): #don't need the 0
winners += c
# columns
for col in range(n):
if np.array_equal(b[0:n, col], trio): #don't need the 0
winners += c
# diagonals
diag1 = np.diag(b)
if np.array_equal(diag1, trio):
winners += c
diag2 = np.diag(np.fliplr(b))
if np.array_equal(diag2, trio):
winners += c
return winners
print(b)
print()
print("Winner(s):", checkGrid(b))
sys.exit(0)
[['X' 'X' ' '] ['X' 'O' ' '] ['X' ' ' 'O']] Winner(s): X
Change lines 38–42 to the following. See Comparisons can be chained.
if (line[26] == "11231"
and line[7] == "Alive"
and line[25].endswith("DE GRAW STREET")
and 100 <= int(line[25].split(maxsplit = 1)[0]) <= 200):
Change the comment in line 16 to
#https://data.cityofnewyork.us/Recreation/BPL-Branches/xmzf-uf2w
Each line of the CSV file contains 16 fields. The first two lines of the file are
branch,address,phone,position,bus,subway,Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday,access,tags,path Arlington Library,"203 Arlington Ave. at Warwick St. Brooklyn, NY 11207",718.277.6105,"40.680456600000, -73.887288700000",Q24;Q56,J,\n10:00am - 6:00pm,\n10:00am - 6:00pm,\n1:00pm - 8:00pm,\n10:00am - 8:00pm,\n10:00am - 6:00pm,\n10:00am - 5:00pm,,Fully accessible,accessible;open now;,https://www.bklynlibrary.org/locations/arlington
Note that the last program in
Street trees
outputs lines in CSV format.
This program, however,
outputs lines in the format of a Python
slice
(with surrounding
[square
brackets])
because of
line
41.
['branch', 'address', 'phone', 'position'] ['Arlington Library', '203 Arlington Ave. at Warwick St. Brooklyn, NY 11207', '718.277.6105', '40.680456600000, -73.887288700000']
When I pointed my browser at
https://drive.google.com/open?id=19KXHctMdKnZXYDzemfLf4FEaAOznHP33&usp=sharing
and logged in to Google,
it was all white because I was looking at Antarctica.
I made the following my by selecting the address field (not the position field).
"""
NYCdeaths.py
New York City Leading Causes of Death
https://data.cityofnewyork.us/Health/New-York-City-Leading-Causes-of-Death/jb7j-dtam/data
"""
import sys
import csv #Comma-separated values. Do not name this Python script csv.py.
import datetime
import urllib.request
import io
welcome = "Hi! This database contains leading causes of death by sex and ethnicity in New York City in 2007-2014."
Ethnicity = [
"Non-Hispanic White",
"Non-Hispanic Black",
"Hispanic",
"Asian and Pacific Islander",
"Not Stated/Unknown",
"Other Race/ Ethnicity"]
url ="https://raw.githubusercontent.com/jhjhjhsu/death/master/New_York_City_Leading_Causes_of_Death.csv"
#user selections: year, sex, ethnicity
print(welcome)
print()
year = input("Which year would you like to look up from 2007-2014? ")
#year = str(year)
sex = input ("Which sex would you like to look up? (1=Male, 2= Female) ")
if sex == "1":
sex = "M"
elif sex == "2":
sex = "F"
else:
print(error) #need edits
print()
print(*Ethnicity, sep = "\n")
print()
ethnicity = input("Which ethnicity would you like to look up? ")
#access data with selected year
try:
fileFromUrl = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print("urllib.error.URLError", error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = fileFromUrl.read() #Read whole file into one big sequenceOfBytes.
fileFromUrl.close()
try:
s = sequenceOfBytes.decode("utf-8") #s is a string, decoding
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
fileFromString = io.StringIO(s)
lines = csv.reader(fileFromString) #or lines = csv.reader(s.splitlines())
SelectedYear = [line for line in lines if line[0] == year] #select year of choice
fileFromString.close()
#filter data by sex and ethnicity
FilteredList = []
for x in SelectedYear:
if x[2] == sex and x[3] == ethnicity:
FilteredList.append(x)
FilteredList.sort(key = lambda x: x[4])
#Print leading causes of death.
#need to print header
print(f"In {year}, the leading causes of death for {ethnicity} {sex} in New York City are:")
for x in FilteredList[:10]:
print(x[2], x[4])
sys.exit(0)
Lines
8,
13–16
are never used.
Remove them.
Line
29
is never reached.
Remove it.
Surround the dangerous
line
18
with
try
and
except.
The
loc
and
bbox_to_anchor
in
line
25
contradict each other.
"""
Read csv file from URL and output stacked bar chart.
Created: 2019-09-22
"""
import matplotlib.pyplot as plt
import pandas as pd
import sys
url = "https://raw.githubusercontent.com/SF19PB1-k1chan/hw12/master/mobile_os.csv"
try:
df = pd.read_csv(url, index_col = 0) #df is a pandas DataFrame.
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
df.plot(kind = 'bar', stacked = True, rot = 0, figsize = (10, 6), legend = False, zorder = 3)
plt.title('Mobile OS Market Share')
plt.ylabel('Percent')
plt.grid(zorder = 0)
plt.legend(bbox_to_anchor = (1.0, 0.5))
plt.show()
This is the code from hw9_17 with bokeh code from here. The same bokeh code, but with an output file instead of an output notebook.
pip3 install bokeh pip3 install IPython pip3 install pandas pip3 install nltk
>>> nltk.download('stopwords')
Before running the program,
download
media_data2.csv.
To see the output,
I had to change
line
56
to
from bokeh.io import show, output_fileand line 59 to
output_file("bars.html") #Create new file in my home directory /Users/myname
Change lines 49–50 from
#Bad idea: don't name a variable "int". high_freq_words = [word[0] for word in listOfTuples[:10]] freq = [int[1] for int in listOfTuples[:10] ]to the following.
listOfTuples
is a
list
of
tuples
and
listOfTuples[:10]
is a much shorter
list
of
tuples.
Each
tuple
consists of one
string
and one
int.
During each loop,
t
is therefore a
tuple
(that’s why I named it
t)
consisting of
one
string
and one
int.
high_freq_words = [t[0] for t in listOfTuples[:10]] #high_freq_words is a list of strings freq = [t[1] for t in listOfTuples[:10]] #freq is a list of ints
[58, 36, 26, 17, 14, 14, 14, 13, 13, 13]
To make sure the macOS microphone is on,
pull down the apple in the upper left corner of the screen
and select
System Preferences… → Sound → Input
and turn up the Input volume.
chown
is “change owner”.
chmod
is “change mode”.
pip3 install SpeechRecognition pip3 show SpeechRecognition Name: SpeechRecognition Version: 3.8.1 Summary: Library for performing speech recognition, with support for several engines and APIs, online and offline. Home-page: https://github.com/Uberi/speech_recognition#readme Author: Anthony Zhang (Uberi) Author-email: azhang9@gmail.com License: BSD Location: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages Requires: Required-by: sudo chown -R $(whoami) /usr/local/share/man/man7 chmod u+w /usr/local/share/man/man7 ls -ld /usr/local/share/man/man7 drwxr-xr-x 26 myname wheel 832 Mar 10 2019 /usr/local/share/man/man7 brew list gdbm pkg-config python3 sqlite openssl python readline xz brew install portaudio brew list gdbm pkg-config python readline xz openssl portaudio python3 sqlite pip3 install PyAudio pip3 show PyAudio Name: PyAudio Version: 0.2.11 Summary: PortAudio Python Bindings Home-page: http://people.csail.mit.edu/hubert/pyaudio/ Author: Hubert Pham Author-email: UNKNOWN License: UNKNOWN Location: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages Requires: Required-by: python3 -m speech_recognition A moment of silence, please... Set minimum energy threshold to 50.8320699286259 Say something! (I said “hello”.) Got it! Now to recognize it... You said hello Say something! Got it! Now to recognize it... You said goodbye Say something! Got it! Now to recognize it... You said stop Say something! Got it! Now to recognize it... You said two houses both alike in dignity Say something! control-c
"""
Print what the user says (or sings).
pip3 install SpeechRecognition
sudo chown -R $(whoami) /usr/local/share/man/man7
chmod u+w /usr/local/share/man/man7
brew install portaudio
pip3 install PyAudio
Python code copied from "Recognize speech input from the microphone" example in
https://github.com/Uberi/speech_recognition#readme
"""
import sys
import speech_recognition
recognizer = speech_recognition.Recognizer()
print(f"The energy threshold is {recognizer.energy_threshold}.")
print(f"The pause threshold is {recognizer.pause_threshold} second(s).")
with speech_recognition.Microphone() as source: #Python context manager
print("Please say something. The microphone is on.")
audio = recognizer.listen(source)
print("You seem to be done speaking, thanks. The microphone is off.")
print(f"size = {len(audio.frame_data):,} bytes")
print(f"sample rate = {audio.sample_rate:,} samples per second")
print(f"sample width = {audio.sample_width} bytes")
try:
seconds = len(audio.frame_data) / (audio.sample_rate * audio.sample_width)
except ZeroDivisionError: #This style is EAFP (vs. LBYL).
pass #Do nothing.
else:
print(f"duration = {seconds:.3f} seconds")
#Recognize speech using Google Speech Recognition.
try:
s = recognizer.recognize_google(audio, language = "en-us")
except speech_recognition.UnknownValueError: #unintelligible
print("Google Speech Recognition could not understand audio", file = sys.stderr)
sys.exit(1)
except speech_recognition.RequestError as error: #no Internet connection
print(f"Could not request results from Google Speech Recognition service: {error}",
file = sys.stderr)
sys.exit(1)
print(f"Google Speech Recognition thinks you said")
print()
print(s)
sys.exit(0)
“IDLE.app” would like to access the microphone. Don’t Allow OK
44100 = 2102 is a perfect square.
The energy threshold is 300. The pause threshold is 0.8 second(s). Please say something. The microphone is on. You seem to be done speaking, thanks. The microphone is off. size = 471,040 bytes sample rate = 44,100 samples per second sample width = 2 bytes duration = 5.341 seconds Google Speech Recognition thinks you said Double Double Toil and Trouble fire burn and cauldron bubble
Five list comprehensions.
pip3 install num2words num2words 123456 -l en one hundred and twenty-three thousand, four hundred and fifty-six num2words 123456 -l en --to ordinal one hundred and twenty-three thousand, four hundred and fifty-sixth
Put the data in a two-dimensional
list
colors
such as
"red",
"orange",
etc.)
"""
Pie chart
https://matplotlib.org/3.1.1/gallery/pie_and_polar_charts/pie_features.html
"""
import matplotlib.pyplot
#List of pie slices, counterclockwise from the startangle.
#The trailing edge (not the center) of the first slice is at the startangle.
#The three fields are label, size (in percent), explode distance from center (in radii).
animals = [
["Rabbits", 15, 0.0],
["Cats", 30, 0.0],
["Dogs", 45, 0.1], #Explode only this slice.
["Hamsters", 10, 0.0]
]
#Get the 3 columns with 3 list comprehensions.
labels = [animal[0] for animal in animals] #Create a list of 4 strings.
sizes = [animal[1] for animal in animals] #Create a list of 4 ints.
explode = [animal[2] for animal in animals] #Create a list of 4 floats.
figure, axes = matplotlib.pyplot.subplots()
figure.canvas.set_window_title("Popular Pets")
axes.axis("equal") #Equal aspect ratio ensures that circle is not stretched or squished.
axes.pie(
sizes,
explode = explode,
labels = labels,
autopct = "%.1f%%", #autopercent, means f"{percent:.1f}%"
#rotatelabels = True,
shadow = True,
startangle = 90 #degrees clockwise from 3 o'clock
)
matplotlib.pyplot.show()
For the old-style string format
"%.1f%%",
see
format.
Should we eliminate the need for the three
list
comprehensions
by changing the
list
of
lists
to
animals = [
["Rabbits", "Cats", "Dogs", "Hamsters"], #labels
[15, 30, 45, 10], #sizes
[0.0, 0.0, 0.1, 0.0] #explode
]
axes.pie(
animals[1], #animals[1] is a list of 4 ints.
explode = animals[2], #animals[2] is a list of 4 floats.
labels = animals[0], #animals[0] is a list of 4 strings.
autopct = "%.1f%%", #autopercent, means f"{percent:.1f}%"
shadow = True,
startangle = 90 #degrees clockwise from 3 o'clock
)
To see the words “Attendance”, “Payroll”, and “team”, you have to stretch the window.
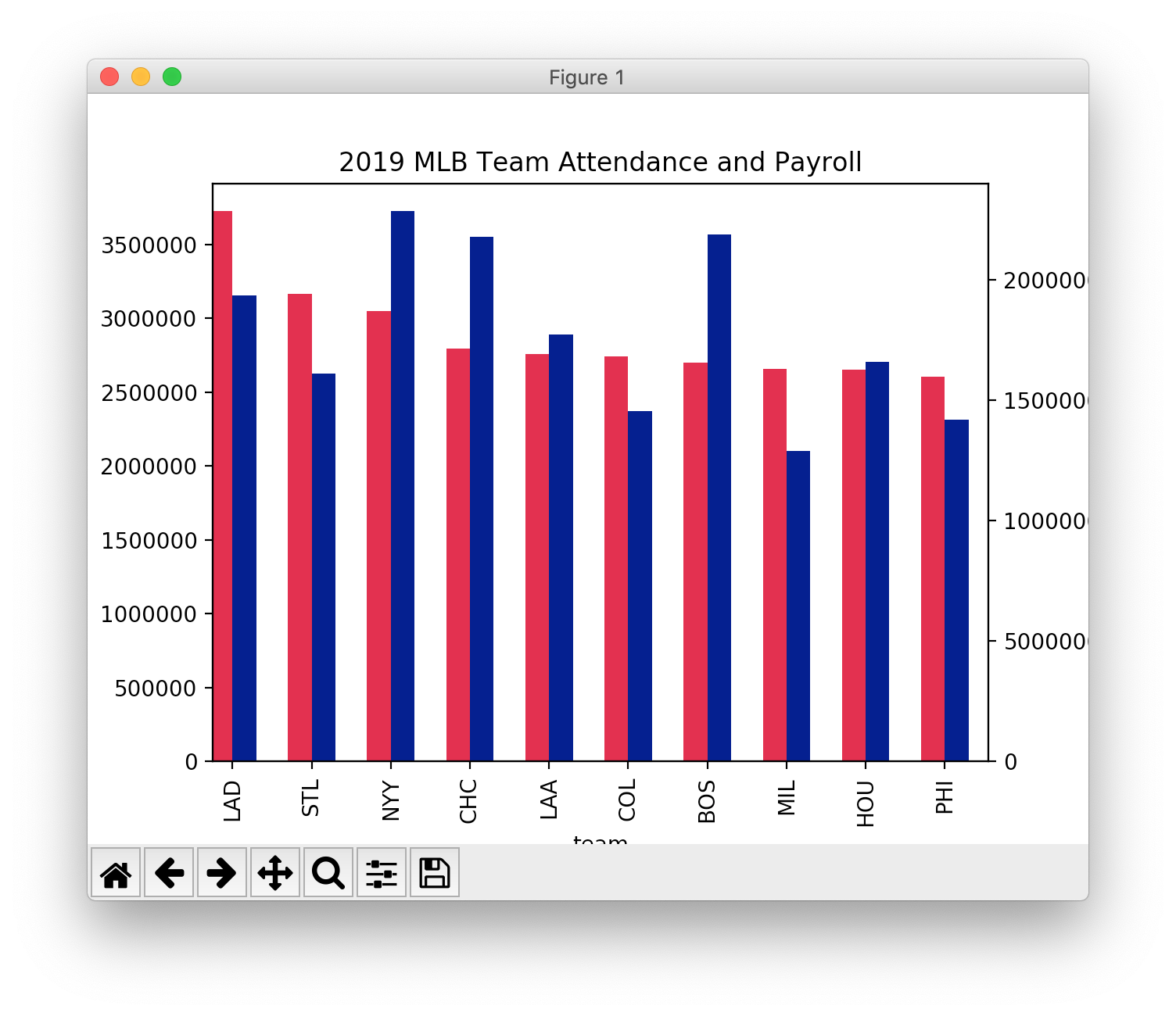
Why is the second picture smaller? How to make it bigger?
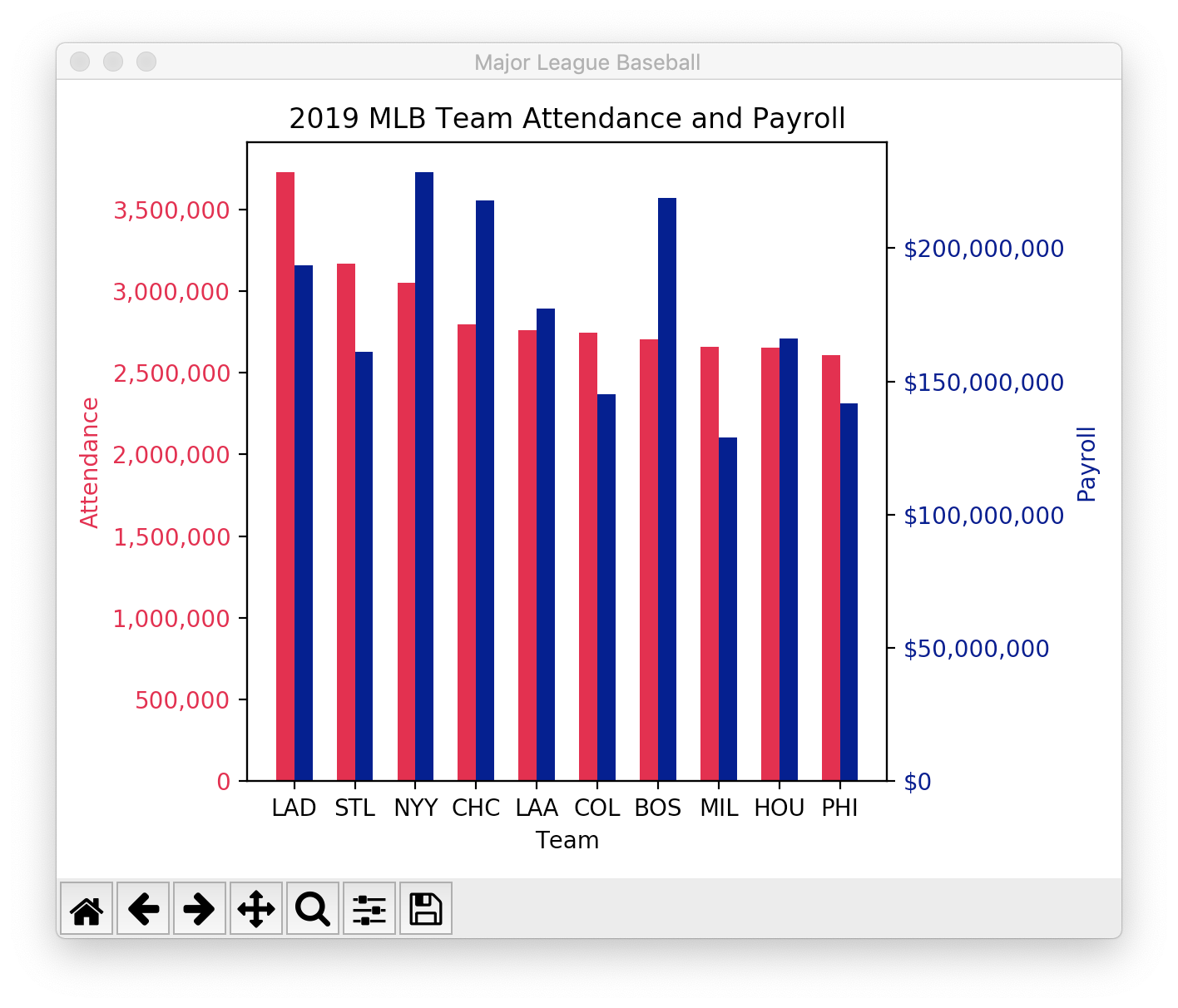
"""
Read csv file from URL and display bar chart.
Created: 2019-09-15
"""
import matplotlib.pyplot as plt
import matplotlib.ticker
import pandas as pd
import numpy as np
url = "https://raw.githubusercontent.com/SF19PB1-k1chan/hw10/master/mlb.csv"
dataFrame = pd.read_csv(url)
n = len(dataFrame) #number of teams
x = np.arange(n) #list of the horizontal posistions of the bars
width = 0.3 #width of each bar
#Create two axes objects that share the same X axis.
figure, axes0 = plt.subplots() #axes0 is the attendance axes.
axes1 = axes0.twinx() #axes1 is the payroll axes.
figure.canvas.set_window_title('Major League Baseball')
axes0.set_title('2019 MLB Team Attendance and Payroll')
axes0.set_xlabel('Team')
axes0.set_xticks(x)
axes0.set_xticklabels(dataFrame.team)
axes0.bar(x - width/2, dataFrame.attendance, width, color = 'crimson', label = 'Attendance')
axes1.bar(x + width/2, dataFrame.payroll, width, color = 'navy', label = 'Payroll')
attendanceFormatter = matplotlib.ticker.FuncFormatter(lambda x, position: f'{x:,.0f}')
payrollFormatter = matplotlib.ticker.FuncFormatter(lambda x, position: f'${x:,.0f}')
axes0.yaxis.set_major_formatter(attendanceFormatter)
axes1.yaxis.set_major_formatter(payrollFormatter)
axes0.tick_params(axis = 'y', labelcolor = 'crimson')
axes1.tick_params(axis = 'y', labelcolor = 'navy')
axes0.set_ylabel('Attendance', color = 'crimson')
axes1.set_ylabel('Payroll', color = 'navy')
figure.tight_layout()
figure.show() #infinite loop
#name, color, position, format
barCharts = [
["Attendance", "crimson", -1, f"{x:,.0f}"],
["Payroll", "navy", +1, f"${x:,.0f}"]
]
pip3 install nltk pip3 show nltk
>>> nltk.download('stopwords')
Download the file
media_data2.csv
to your Mac.
import
string
paragraphs = dataFrame.Body
"""
Output a list of the words from multiple cells in a CSV, in order of the most
frequent. Ignores common words.
Sample output:
58 br
36 banking
26 content
17 baas
14 across
14 amp
14 open
etc.
"""
import sys
import collections
import requests
import pandas
import nltk
from nltk.corpus import stopwords
import string
# from nltk.tokenize import word_tokenize - This looks to be a significantly
# easier implementation of tokenizing words vs the string punctuation solution.
#nltk.download('punkt')
with open('media_data2.csv', newline = '', encoding = 'mac_roman') as csvfile:
dataFrame = pandas.read_csv(csvfile)
#Have a look at the data.
print(dataFrame.Outlet)
print()
print(dataFrame.Title)
print()
print(f"type(dataFrame.Body) = {type(dataFrame.Body)}")
print(f"len(dataFrame.Body) = {len(dataFrame.Body)}")
print()
punctuation = string.punctuation + "\u201C\u201D" #double quotes “ ”
paragraphs = dataFrame.Body
strippedWords = [word.strip(punctuation) for word in " ".join(paragraphs).split()]
lowerWords = [word.lower() for word in strippedWords if word]
# Clean list to make sure stop words are not counted
stop_words = set(stopwords.words('english')) #"i", "me", "my", "myself", "we", etc.
cleanListOfWords = [word for word in lowerWords if word not in stop_words]
#Counter is like a dict. Keys are words, values are counts.
counter = collections.Counter(cleanListOfWords)
listOfTuples = counter.most_common()
for word, i in listOfTuples[:30]:
print(f"{i:2} {word}")
sys.exit(0)
0 Forbes 1 MRO Network 2 EEWeb Name: Outlet, dtype: object 0 Telecoms Are In A Tricky Spot„Can Tech Save ... 1 Blockchain Tipped For Leasing Impact 2 Are you ready for CES 2019? Name: Title, dtype: object type(dataFrame.Body) = <class 'pandas.core.series.Series'> len(dataFrame.Body) = 3 26 ai 23 technology 22 data 19 blockchain 17 world 17 5g 15 ces 14 telecoms 13 make 13 digital 12 networks 12 one 12 tesla 12 industry 11 using 11 new 11 systems 11 companies 11 2019 11 research 10 smart 10 much 10 use 10 capacity 10 many 10 gpt-2 10 Ñ 10 consumers 9 home 9 customers
The
urlFile
is of type
http.client.HTTPResponse.
When I tried to give the
urlFile
directly to the
PyPDF2.PdfFileReader,
I got the exception
io.UnsupportedOperation: seek
(Seeking meets rewinding and jumping backwards and forwards.)
So I copied the contents of the
urlFile
into an
io.BytesIO,
which is capable of seeking.
"""
Extract information from a file in PDF format.
"""
import sys
import io
import urllib.request
import PyPDF2
url = "http://www.pdf995.com/samples/pdf.pdf"
try:
urlFile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = urlFile.read()
urlFile.close()
#Access the sequence of bytes as if it were a file.
bytesFile = io.BytesIO(sequenceOfBytes)
reader = PyPDF2.PdfFileReader(bytesFile)
print(f"numPages = {reader.numPages}")
for key, value in reader.documentInfo.items(): #reader.documentInfo is a dict
print(f"{key[1:]:12} {value}") #key is a string
bytesFile.close()
sys.exit(0)
numPages = 5 Producer GNU Ghostscript 7.05 Title PDF Creator Pdf995 CreationDate 12/12/2003 17:30:12 Author Software 995 Subject Create PDF with Pdf 995 Keywords pdf, create pdf, software, acrobat, adobe
"""
Convert text to speech in different languages. Requires pip3 install gtts
"""
import sys
import os
import tempfile
import playsound
import gtts #Google Text-To-Speech
print("We're going to say what you type.")
print("Here are the available languages:")
print()
for key, value in gtts.lang.tts_langs().items(): #a dict
print(key, value)
print()
lang = input("Please enter the code for your language (e.g., en-us): ")
text = input("Please enter some text: ")
print()
try:
textToSpeech = gtts.gTTS(text = text, lang = lang, slow = True)
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
# Save the audio in a temporary file with a name.
temporaryFile = tempfile.NamedTemporaryFile()
textToSpeech.save(temporaryFile.name)
print("Here is the temporary file:")
print(os.popen(f"ls -l {temporaryFile.name}").read(), end = "")
print(os.popen(f"file {temporaryFile.name}").read(), end = "")
# Play and erase the temporary file.
try:
playsound.playsound(temporaryFile.name, True) #Requires a filename or URL.
except OSError as error:
print(error, file = sys.stderr)
sys.exit(1)
finally:
temporaryFile.close() #Erase the temporary file.
sys.exit(0)
We're going to say what you type. Here are the available languages: af Afrikaans sq Albanian ar Arabic hy Armenian bn Bengali bs Bosnian ca Catalan hr Croatian cs Czech da Danish nl Dutch en English eo Esperanto et Estonian tl Filipino fi Finnish fr French de German el Greek gu Gujarati hi Hindi hu Hungarian is Icelandic id Indonesian it Italian ja Japanese jw Javanese kn Kannada km Khmer ko Korean la Latin lv Latvian mk Macedonian ml Malayalam mr Marathi my Myanmar (Burmese) ne Nepali no Norwegian pl Polish pt Portuguese ro Romanian ru Russian sr Serbian si Sinhala sk Slovak es Spanish su Sundanese sw Swahili sv Swedish ta Tamil te Telugu th Thai tr Turkish uk Ukrainian ur Urdu vi Vietnamese cy Welsh zh-cn Chinese (Mandarin/China) zh-tw Chinese (Mandarin/Taiwan) en-us English (US) en-ca English (Canada) en-uk English (UK) en-gb English (UK) en-au English (Australia) en-gh English (Ghana) en-in English (India) en-ie English (Ireland) en-nz English (New Zealand) en-ng English (Nigeria) en-ph English (Philippines) en-za English (South Africa) en-tz English (Tanzania) fr-ca French (Canada) fr-fr French (France) pt-br Portuguese (Brazil) pt-pt Portuguese (Portugal) es-es Spanish (Spain) es-us Spanish (United States) Please enter the code for your language (e.g., en-us): es Please enter some text: Yo no soy marinero. Soy capitan. Here is the temporary file: -rw------- 1 myname mygroup 13632 Sep 12 11:25 /var/folders/pb/rx_csw656h95vzh_nk8ndt180000gn/T/tmp5cadx4zm /var/folders/pb/rx_csw656h95vzh_nk8ndt180000gn/T/tmp5cadx4zm: MPEG ADTS, layer III, v2, 32 kbps, 24 kHz, Monaural
Since the timestamp did not have hour, minute, second,
I called the
today
and
strftime
methods of class
datetime.date,
not the
today
and
strftime
methods of class
datetime.datetime.
"""
This program is rng.py. Save it on your Desktop.
Create list of 100 random numbers and write it to text file.
Created: 2019-09-11
"""
import sys
import datetime
import random
import getpass #get password
userName = getpass.getuser()
timeStamp = datetime.date.today().strftime("%Y%m%d")
fileName = f"/Users/{userName}/Desktop/temp_{timeStamp}.txt"
try:
outFile = open(fileName, "w") #"w" for "write" makes this an output file
except BaseException as error:
print(error, file = sys.stderr)
sys.exit(1)
# Create list of 100 random integers between 1 and 999 inclusive.
myList = [random.randint(1, 1000) for i in range(100)]
# Output the list to the text file.
for i in myList:
#Convert i from int to string, print it, and print a newline.
print(i, file = outFile)
outFile.close()
sys.exit(0)
"""
Execute the Python program rng.py.
Created: 2019-09-11
"""
import sys
import os #operating system
import getpass #get password
userName = getpass.getuser()
scriptName = f"/Users/{userName}/Desktop/rng.py"
if not os.path.exists(scriptName):
print(f"File not found: {scriptName}", file = sys.stderr)
sys.exit(1)
command = f"/Library/Frameworks/Python.framework/Versions/3.7/bin/python3 {scriptName}"
number = os.system(command) #number is a two-byte integer
loByte = number & 0xFF #& is bitwise and
if loByte != 0:
print(f"child was killed by signal number {loByte & 0x7F} ", end = "")
print("before it could produce an exit status.")
sys.exit(1)
exitStatus = number >> 8 #>> is right shift
print(f"child's exit status = {exitStatus}")
sys.exit(exitStatus)
"""
Flatten a deeply nested list.
"""
import sys
import functools
mylist = [
[
[
[10, 20],
[30, 40],
],
[
[50, 60],
[70, 80],
],
],
[
[
[90, 100],
[110, 120],
],
[
[130, 140],
[150, 160],
],
],
]
def recursiveFlatten1(originalList):
assert isinstance(originalList, list)
flattenedList = []
for item in originalList:
if isinstance(item, list):
flattenedList += recursiveFlatten1(item) #or flattenedList.extend(recursiveFlatten1(item))
else:
flattenedList += [item] #or flattenedList.append(item)
return flattenedList
def recursiveFlatten2(originalList):
assert isinstance(originalList, list)
return functools.reduce(
lambda flattenedList, item: flattenedList + (recursiveFlatten2(item) if isinstance(item, list) else [item]),
originalList,
[]
)
print(recursiveFlatten1(mylist))
print(recursiveFlatten2(mylist))
sys.exit(0)
[10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160] [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160]
Eliminate the button. Display the symbol as soon as the user selects a company from the menu.
Combine the two
lists
into a single
list
of
lists.
I put
None
into
this list
only to give January index 1,
February index 2,
December index 12.
"""
ticker.py
Provide stock ticker symbols for some of the top companies on the S&P 500.
"""
import sys
import tkinter
companies = [ #a list of 6 lists
["AAPL", "Apple Inc."],
["MSFT", "Microsoft Corp."],
["AMZN", "Amazon.com Inc."],
["FB", "Facebook Inc."],
["BRK", "Berkshire Hathaway Inc."],
["GOOG", "Google (aka Alphabet Inc.)"]
]
names = [company[1] for company in companies] #a list of 6 strings
root = tkinter.Tk()
root.title("Stock ticker symbols")
#Labels:
compLabel = tkinter.Label(text = "Choose company name:", anchor = "e", padx = 5)
compLabel.grid(row = 0, column = 0, sticky = "e")
mytikLabel = tkinter.Label(text = "Ticker:", anchor = "e", padx = 5)
mytikLabel.grid(row = 1, column = 0, sticky = "e")
tikLabel = tkinter.Label(text = companies[0][0], anchor = "w", padx = 5,
bg = "white", fg = "green", font = (None, 20))
tikLabel.grid(row = 1, column = 1, sticky = "ew")
#Variable:
com = tkinter.StringVar(root)
com.set(companies[0][1]) #default value
#Menu:
def fetchTicker(name):
try:
i = names.index(name)
except ValueError as error:
print(error, file = sys.stderr)
sys.exit(1)
tikLabel["text"] = companies[i][0]
compMenu = tkinter.OptionMenu(root, com, *names, command = fetchTicker)
compMenu.grid(row = 0, column = 1, sticky = "ew")
tkinter.mainloop()
pip3 install matplotlib pip3 install numpy
"""
Read image from URL and transform (horizontal flip, vertical flip, grayscale).
Created: 2019-09-08
"""
import sys
import matplotlib.pyplot
import matplotlib.image
import numpy
url = "http://oit2.scps.nyu.edu/~meretzkm/python/string/escalus2.png"
try:
image = matplotlib.image.imread(url)
except FileNotFoundError as error:
print(error, file = sys.stderr)
sys.exit(1)
#rows is a list containing 2 smaller lists, because we want 2 rows.
#Each smaller list contains 2 even smaller lists, because we want 2 columns.
#Each even smaller list contains 3 strings.
rows = [
[["Original", "image", None], ["Horizontal Flip", "numpy.fliplr(image)", None]],
[["Vertical Flip", "numpy.flipud(image)", None], ["Grayscale", "image[:,:,1]", "gray"]]
]
figure, axarr = matplotlib.pyplot.subplots(len(rows[0]), len(rows))
for y, row in enumerate(rows):
for x, col in enumerate(row):
axarr[x, y].set_title(col[0])
axarr[x, y].imshow(eval(col[1]), cmap = col[2])
axarr[x, y].axis("off")
figure.show()
sys.exit(0)
The original program has to discard the word AT
(line
32)
and has to discard duplicates with the
set
in
line
39.
Open in browser: https://www.w3.org/TR/PNG/iso_8859-1.txt Press Enter to continue... Count of words: 858 Count of sentences: 3 Count of numbers: 60 ['20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79'] Count of hex codes: 130 ['2A', '2B', '2C', '2D', '2E', '2F', '3A', '3B', '3C', '3D', '3E', '3F', '4A', '4B', '4C', '4D', '4E', '4F', '5A', '5B', '5C', '5D', '5E', '5F', '6A', '6B', '6C', '6D', '6E', '6F', '7A', '7B', '7C', '7D', '7E', 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7', 'A8', 'A9', 'AA', 'AB', 'AC', 'AD', 'AE', 'AF', 'B0', 'B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8', 'B9', 'BA', 'BB', 'BC', 'BD', 'BE', 'BF', 'C0', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'CA', 'CB', 'CC', 'CD', 'CE', 'CF', 'D0', 'D1', 'D2', 'D3', 'D4', 'D5', 'D6', 'D7', 'D8', 'D9', 'DA', 'DB', 'DC', 'DD', 'DE', 'DF', 'E0', 'E1', 'E2', 'E3', 'E4', 'E5', 'E6', 'E7', 'E8', 'E9', 'EA', 'EB', 'EC', 'ED', 'EE', 'EF', 'F0', 'F1', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8', 'F9', 'FA', 'FB', 'FC', 'FD', 'FE', 'FF']
"""
Read text file from URL and output number of words, sentences, hexadecimal numbers that
have no letters, and hexadecinal numbers that have letters.
Created: 2019-09-08
"""
import sys
import requests
import webbrowser
import re #regular expressions
url = "https://www.w3.org/TR/PNG/iso_8859-1.txt"
try:
response = requests.get(url)
except requests.exceptions.RequestException as error:
print(error, file = sys.stderr)
sys.exit(1)
print(f"Open in browser: {url}")
input("Press Enter to continue... ")
webbrowser.open(url)
data = response.text
lines = data.splitlines()[8:] #Discard the first 8 lines in the file.
characters = []
#The file consists of two columns. The first column is 32 characters wide.
for line in lines:
characters.append(line[:32])
characters.append(line[32:])
#Find a two-digit hexadecimal (base 16) number.
try:
regularExpression = re.compile(r'[A-F0-9]{2}')
except re.error as error:
print(error, file = sys.stderr)
sys.exit(1)
#hexNumbers is a list of two-character strings.
hexNumbers = [regularExpression.match(character).group()
for character in characters
if regularExpression.match(character)]
#Some of the hexadecimal numbers happen to be spelled entirely with decimal digits.
decimalNumbers = [hexNumber for hexNumber in hexNumbers if hexNumber.isdecimal()]
otherNumbers = [hexNumber for hexNumber in hexNumbers if not hexNumber.isdecimal()]
#decimalNumbers and otherNumbers are lists of two-character strings.
#Sort them in order of the values of the numbers portrayed in those strings.
def score(n):
return int(n, base = 16)
decimalNumbers.sort(key = score)
otherNumbers.sort(key = score)
print()
print(f'Count of words: {len(data.split())}')
print()
print(f'Count of sentences: {data.count(".")}')
print()
print(f'Count of hex numbers that have no letters: {len(decimalNumbers)}')
print()
print(decimalNumbers)
print()
print(f'Count of hex numbers that have letters: {len(otherNumbers)}')
print()
print(otherNumbers)
sys.exit(0)
Open in browser: https://www.w3.org/TR/PNG/iso_8859-1.txt Press Enter to continue... Count of words: 858 Count of sentences: 3 Count of hex numbers that have no letters: 60 ['20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79'] Count of hex numbers that have letters: 130 ['2A', '2B', '2C', '2D', '2E', '2F', '3A', '3B', '3C', '3D', '3E', '3F', '4A', '4B', '4C', '4D', '4E', '4F', '5A', '5B', '5C', '5D', '5E', '5F', '6A', '6B', '6C', '6D', '6E', '6F', '7A', '7B', '7C', '7D', '7E', 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7', 'A8', 'A9', 'AA', 'AB', 'AC', 'AD', 'AE', 'AF', 'B0', 'B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8', 'B9', 'BA', 'BB', 'BC', 'BD', 'BE', 'BF', 'C0', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'CA', 'CB', 'CC', 'CD', 'CE', 'CF', 'D0', 'D1', 'D2', 'D3', 'D4', 'D5', 'D6', 'D7', 'D8', 'D9', 'DA', 'DB', 'DC', 'DD', 'DE', 'DF', 'E0', 'E1', 'E2', 'E3', 'E4', 'E5', 'E6', 'E7', 'E8', 'E9', 'EA', 'EB', 'EC', 'ED', 'EE', 'EF', 'F0', 'F1', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8', 'F9', 'FA', 'FB', 'FC', 'FD', 'FE', 'FF']
The output would be easier to read in the columns we created with
zip
here.
pip3 install playsound
Traceback (most recent call last):
File "/Users/myname/python/junk.py", line 21, in <module>
playsound.playsound(file, True)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/playsound.py", line 55, in _playsoundOSX
from AppKit import NSSound
ModuleNotFoundError: No module named 'AppKit'
pip3 install pyobjc pip3 install AppKit
"""
play_ynwa.py.py
Play "You'll Never Walk Alone".
"""
import sys
import time
import playsound
#pluck guitar string
file = "/Library/Frameworks/Python.framework/Versions/3.7" \
"/lib/python3.7/test/audiodata/pluck-pcm24.au"
#Chinese sound effect
url1 = "http://oit2.scps.nyu.edu/~meretzkm/swift/button/chinese.mp3"
#"You'll Never Walk Alone"
url2 = "http://www.fcsongs.com/uploads/audio" \
"/Liverpool%20FC%20-%20You%20Will%20Never%20Walk%20Alone.mp3"
try:
playsound.playsound(file, True)
time.sleep(1)
playsound.playsound(url1, True)
time.sleep(1)
playsound.playsound(url2, True)
except OSError as error:
print(error, file = sys.stderr)
sys.exit(1)
sys.exit(0)
pip3 install googletrans pip3 list pip3 show googletrans Name: googletrans Version: 2.4.0 Summary: Free Google Translate API for Python. Translates totally free of charge. Home-page: https://github.com/ssut/py-googletrans Author: SuHun Han Author-email: ssut@ssut.me License: MIT Location: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages Requires: requests Required-by:
Then read the documentation in the README.rst file.
"""
translate.py
Loop through the lines of a text file downloaded from the Internet.
Convert each line from a sequence of bytes to a string of characters and translate them.
need to run pip install googletrans on BMCC Mac, or py -3 -m pip install googletrans
"""
# Prob doesnt work yet, couldnt test it at work because of firewalls
# Works now!
import sys
import urllib.request
import googletrans
language_code = """\
Afrikaans af
Albanian sq
Arabic ar
Belarusian be
Bulgarian bg
Catalan ca
Chinese Simplified zh-CN
Chinese Traditional zh-TW
Croatian hr
Czech cs
Danish da
Dutch nl
English en
Estonian et
Filipino tl
Finnish fi
French fr
Galician gl
German de
Greek el
Hebrew iw
Hindi hi
Hungarian hu
Icelandic is
Indonesian id
Irish ga
Italian it
Japanese ja
Korean ko
Latvian lv
Lithuanian lt
Macedonian mk
Malay ms
Maltese mt
Norwegian no
Persian fa
Polish pl
Portuguese pt
Romanian ro
Russian ru
Serbian sr
Slovak sk
Slovenian sl
Spanish es
Swahili sw
Swedish sv
Thai th
Turkish tr
Ukrainian uk
Vietnamese vi
Welsh cy
Yiddish yi
"""
print("We're going to translate a verse from Romeo and Juliet into another language that you select")
print("Language Code")
print("-------- ----")
print(language_code)
language = input("Please select the language code: ")
url = "http://oit2.scps.nyu.edu/~meretzkm/python/string/romeo.txt"
try:
lines = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
translator = googletrans.Translator()
for line in lines: #line is a sequence of bytes.
try:
s = line.decode("utf-8")
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
translation = translator.translate(s, src = "en", dest = language)
print(translation.text)
lines.close()
sys.exit(0)
Please select the language code: es Bajo pena de tortura, de esas manos ensangrentadas Lanza tus armas apagadas al suelo, Y escucha la frase de tu príncipe movèd.
Please select the language code: iw על כאב עינויים, מאותן ידיים עקובות מדם זרוק את כלי הנשק הטעויות שלך ארצה, ושמע את המשפט של נסיך המובחר שלך.
"""
MarvelMovies.py
Sort Marvel movies by increasing gross.
"""
import sys
import urllib.request
#import marvel movies data
url = "http://oit2.scps.nyu.edu/~meretzkm/python/SF19PB1/marvel.txt"
try:
infile = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(error, file = sys.stderr)
sys.exit(1)
sequenceOfBytes = infile.read()
infile.close()
try:
s = sequenceOfBytes.decode("utf-8") #Convert sequence of bytes to string of characters.
except UnicodeError as error:
print(error, file = sys.stderr)
sys.exit(1)
films = s.splitlines()
#Print the first line and then exclude it from the list to be sorted.
print(films[0])
films = films[1:] #or del films[0]
def score(s):
fields = s.split(",") #fields is a list of strings
return float(fields[0])
films.sort(key = score)
for film in films:
fields = film.split(",")
gross = float(fields[0])
name = fields[1]
print(f"${gross:16,.2f} {name}")
sys.exit(0)
WorldwideGross,Film $ 263,427,551.00 The Incredible Hulk $ 370,569,774.00 Captain America: The First Avenger $ 449,326,618.00 Thor $ 519,311,965.00 Ant-Man $ 585,174,222.00 Iron Man $ 622,674,139.00 Ant-Man and the Wasp $ 623,933,331.00 Iron Man 2 $ 644,571,402.00 Thor: The Dark World $ 677,718,395.00 Doctor Strange $ 714,264,267.00 Captain America: The Winter Soldier $ 773,328,629.00 Guardians of the Galaxy $ 853,977,126.00 Thor: Ragnarok $ 863,756,051.00 Guardians of the Galaxy Vol. 2 $ 880,166,924.00 Spider-Man: Homecoming $1,124,735,841.00 Spider-Man: Far From Home $1,128,274,794.00 Captain Marvel $1,153,304,495.00 Captain America: Civil War $1,214,811,252.00 Iron Man 3 $1,346,913,161.00 Black Panther $1,405,403,694.00 Avengers: Age of Ultron $1,518,812,988.00 Marvel's The Avengers $2,048,359,754.00 Avengers: Infinity War $2,796,250,059.00 Avengers: Endgame
Shirley Ellis, The Name Game. See Beer.
Please type a name: Mark Mark,Mark,bo-bark Banana-fana fo-fark Fee-fi-mo-mark Mark!! Please type a name:
"""
name_game.py
Translate the input name to the Name song.
"""
#A four-line string containing six pockets.
import sys
verse = """\
{}, {}, bo-b{}
Banana-fana fo f{}
Fee-fi-mo-{}
{}!!
"""
while True:
try:
name = input("Please type a name: ")
except EOFError:
sys.exit(0)
rest = name[1:]
print(verse.format(name, name, rest, rest, rest, name))
print()
"""
ZodiacSign.py
Find your zodiac sign.
"""
import sys
import datetime
print("Find your Zodiac Sign.")
s = input("When is your birthday? Enter as mm,dd: ")
listOfNumbers = s.split(",")
if len(listOfNumbers) != 2:
print("Needed two numbers, separated by a comma.")
sys.exit(1)
try:
month = int(listOfNumbers[0])
except ValueError as error:
print(error)
sys.exit(1)
try:
day = int(listOfNumbers[1])
except ValueError as error:
print(error)
sys.exit(1)
year = 2000 #Pick a year that has a February 29.
birthday = datetime.datetime(year, month, day)
signs = [
[ 1, 19, "Capricorn"],
[ 2, 18, "Aquarius"],
[ 3, 20, "Pisces"],
[ 4, 19, "Aries"],
[ 5, 20, "Taurus"],
[ 6, 20, "Gemini"],
[ 7, 22, "Cancer"],
[ 8, 22, "Leo"],
[ 9, 22, "Virgo"],
[10, 22, "Libra"],
[11, 21, "Scorpio"],
[12, 21, "Sagittarius"],
[12, 31, "Capricorn"]
]
for sign in signs:
d = datetime.datetime(year, sign[0], sign[1])
if birthday <= d:
break
print(f"You are a {sign[2]}!")
sys.exit(0)
"""
ZodiacSign.py
Find your zodiac sign. Select your birth month and day from tkinter menus.
"""
import sys
import datetime
import tkinter
monthNames = [
None,
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
]
signs = [
[ 1, 19, "Capricorn"],
[ 2, 18, "Aquarius"],
[ 3, 20, "Pisces"],
[ 4, 19, "Aries"],
[ 5, 20, "Taurus"],
[ 6, 20, "Gemini"],
[ 7, 22, "Cancer"],
[ 8, 22, "Leo"],
[ 9, 22, "Virgo"],
[10, 22, "Libra"],
[11, 21, "Scorpio"],
[12, 21, "Sagittarius"],
[12, 31, "Capricorn"]
]
root = tkinter.Tk()
root.title("Find your Zodiac Sign.")
#Labels:
monthLabel = tkinter.Label(text = "What is your birth month?", anchor = "w", padx = 5)
monthLabel.grid(row = 0, column = 0)
dayLabel = tkinter.Label(text = "What is your birth day?", anchor = "w", padx = 5)
dayLabel.grid(row = 1, column = 0, sticky = "ew") #east west
signLabel = tkinter.Label(anchor = "w", padx = 5)
signLabel.grid(row = 2, column = 1, sticky = "ew")
#Variables:
month = tkinter.StringVar(root)
month.set(monthNames[1]) #default value
day = tkinter.IntVar(root)
day.set(1) #default value
#Menus:
def erase(monthName):
signLabel["text"] = ""
monthMenu = tkinter.OptionMenu(root, month, *monthNames[1:], command = erase)
monthMenu.grid(row = 0, column = 1, sticky = "ew")
dayMenu = tkinter.OptionMenu(root, day, *range(1, 32), command = erase)
dayMenu.grid(row = 1, column = 1, sticky = "ew")
#Button:
def buttonPressed():
monthName = month.get()
monthNumber = monthNames.index(monthName)
year = 2000 #Pick a year that has february 29.
birthday = datetime.datetime(year, monthNumber, day.get())
for sign in signs:
if birthday <= datetime.datetime(year, sign[0], sign[1]):
break
signLabel["text"] = sign[2]
button = tkinter.Button(root, text = "Press this button.",
anchor = "w", padx = 5, command = buttonPressed)
button.grid(row = 2, column = 0, sticky = "we")
tkinter.mainloop()
r
does nothing because the filename has no backslashes.
f = open(r"/Users/" + userNm + "/Desktop/" + fileNm)
f = open(f"/Users/{userNm}/Desktop/{fileNm}")
print("Error reading input file!")
to
exceptionInfo = sys.exc_info()
print("Error reading input file!", exceptionInfo[1], file = sys.stderr)
Error reading input file! [Errno 2] No such file or directory: '/Users/myname/Desktop/oliver_twist.txt'
Error reading input file! [Errno 13] Permission denied: '/Users/myname/Desktop/oliver_twist.txt'To see the error numbers,
man errnoEven better, check for
FileNotFoundError
and
PermissionError
as in
One big string.
len
function to count the number of words that are made out of letters
after their leading and trailing
punctuation
has been
stripped
off.
contentSplit = content.split() # Calculate total number of words wordTotal = sum([i.strip(string.punctuation).isalpha() for i in contentSplit])
words = content.split() # Calculate total number of words. wordTotal = len([None for word in words if word.strip(string.punctuation).isalpha()])Without a list comprehension:
words = content.split() #list of strings alphabeticWords = [] #start with an empty list for word in words: strippedWord = word.strip(string.punctuation) if strippedWord.isalpha(): alphabeticWords.append(None) wordTotal = len(alphabeticWords)
# Create search list {a-z}
wordCounter = {}.fromkeys(string.ascii_lowercase,0)
# Count number of words beginning with letters in search list.
for word in words:
wordCounter[word[0].lower()]+=1
We saw
collections.Counter
below
on August 27.
Remember to
import
collections.
wordCounter = collections.Counter([word[0].lower() for word in words])
\n)
at the
end
of the string,
not at the beginning.
Do not print one space before the file contents (“Chapter I”).
print("\nFile contents:") print("\n",content) print("\nNumber of words: " + str(wordTotal)) print("\nNumber of words beginning with:") for i in wordCounter: print(i,":", f"{wordCounter[i]:2}")
print() #Output a newline. print("File contents:") print() print(content) print(f"Number of words: {wordTotal}") print() print("Number of words beginning with:") for letter in string.ascii_lowercase: print(f"{letter}: {wordCounter[letter]:2}")
Write the comments in the imperative tense.
Display the color in a
tkinter
Label,
not in an
Entry.
Display the digits in a monospace font to get the columns to line up.
To left justify,
anchor = "w"
for “west”.
"""
Store the hex code of different color shades of cyan into a list.
Compute the RGB codes of each color. Display a color code chart.
Created on 2019-08-28
"""
import tkinter
import textwrap
#A list containing 13 smaller lists. Each smaller list contains 2 strings.
colors = [
["E0FFFF", "light cyan"],
["00FFFF", "cyan"],
["00FFFF", "aqua"],
["7FFFD4", "aquamarine"],
["66CDAA", "medium aquamarine"],
["AFEEEE", "pale turquoise"],
["40E0D0", "turquoise"],
["48D1CC", "medium turquoise"],
["00CED1", "dark turquoise"],
["20B2AA", "light seagreen"],
["5F9EA0", "cadet blue"],
["008B8B", "dark cyan"],
["008080", "teal"]
]
root = tkinter.Tk()
root.title("Cyan Color Codes Chart")
for row, color in enumerate(colors):
hexs = textwrap.wrap(color[0], 2) #Split the hex string into a list of 3 two-character strings.
d = [int(hex, 16) for hex in hexs] #Create a list of 3 ints using a list comprehension.
color.append(f"rgb({d[0]:3}, {d[1]:3}, {d[2]:3})") #or color.append("rgb({:3}, {:3}, {:3})".format(*d))
label = tkinter.Label(bg = f"#{color[0]}", relief = tkinter.SUNKEN, width = 10)
label.grid(row = row, column = 0)
for column, text in enumerate(color, start = 1):
label = tkinter.Label(text = text, font = "TkFixedFont", relief = tkinter.RIDGE,
anchor = "w", padx = 5, width = 18)
label.grid(row = row, column = column)
tkinter.mainloop()
Make it possible to change the size of the flag
by changing only one statement
(height =).
Make it possible to change the number of stripes
by changing only one statement
(n =).
Complain if orientation
(V
vs.
(H)
is unrecognized.
"""
build_tri_flag.py
Build a tricolour flag using tkinter Canvas widget.
"""
import sys
import tkinter #in Python2, the t was uppercase
n = 3 #number of colours
print("Let's build a tri-colour flag")
orientation = input("Would you like horizontal or vertical stripes? Enter H or V: ")
colours = [] #List is born empty, but it will grow.
for i in range(n):
colour = input(f"Pick colour number {i + 1}: ")
colours.append(colour)
#The root widget is the window that will contain everything we draw.
root = tkinter.Tk()
root.title("Tri-colour Flag")
#Dimensions of entire flag, in pixels.
height = 100 * n
width = 2 * height
root.geometry(f"{width}x{height}")
canvas = tkinter.Canvas(root, highlightthickness = 0)
if orientation == "V":
stripeWidth = width // n
for i, colour in enumerate(colours):
canvas.create_rectangle(i * stripeWidth, 0, (i + 1) * stripeWidth, height,
width = 0, fill = colour)
elif orientation == "H":
stripeHeight = height // n
for i, colour in enumerate(colours):
canvas.create_rectangle(0, i * stripeHeight, width, (i + 1) * stripeHeight,
width = 0, fill = colour)
else:
print("Orientation must be V or H.")
sys.exit(1)
#Make the canvas visible by packing it into the root.
canvas.pack(expand = tkinter.YES, fill = "both")
#If the flag had buttons, checkboxes, etc.,
#the mainloop would let them respond to touches.
root.mainloop()
Make it possible to add another currency
just by adding one item to the
rates
list.
"""
currency.py
Convert US dollars to other currencies.
Also time how long it took program to run.
"""
import sys
import timeit
rates = [
["EUR", .90],
["GBP", .82],
["CNY", 7.14]
]
def my_function():
print("Convert your dollars to EUR, GBP, and CNY")
print()
while True:
try:
dol = float(input("How many US Dollars do you have? "))
except EOFError:
sys.exit(1)
except KeyboardInterrupt:
sys.exit(1)
except ValueError:
print()
print("Please enter a numerical amount.")
else:
break
print(f"{dol:.2f} USD converts to:")
print()
for rate in rates:
print(f"{rate[1] * dol:5.2f} {rate[0]}")
print()
secs = timeit.timeit(my_function, number = 1)
print(f"Note: this program took {secs:.2f} seconds to run.")
sys.exit(0)
"""
Prompt the user to select one number from a list of random numbers.
The computer will also select a number. The higher mod 10 number wins.
Created on 2019-08-28
"""
import sys
import random
# Generate random sample of 25 numbers.
numList = random.sample(range(1, 100), 25)
#Print the numList in 5 columns.
for i, num in enumerate(numList):
if i % 5 == 4:
print(num)
else:
print(num, end = " ")
userNum = int(input("Select one number from above: "))
if userNum not in numList:
print("Invalid input!")
sys.exit(1)
computerNum = random.choice(numList)
userDigit = userNum % 10 #rightmost digit of userNum
computerDigit = computerNum % 10 #rightmost digit of computerNum
print(f"""\
User: {userNum}
User mod 10: {userDigit}
Computer: {computerNum}
Computer mod 10: {computerDigit}
""")
if userDigit > computerDigit:
print("Player wins!")
elif userDigit < computerDigit:
print("Computer wins!")
else:
print("Tie game.")
sys.exit(0)
42 61 69 30 5 46 17 44 35 10 57 7 34 66 32 68 1 6 82 76 89 90 2 97 92 Select one number from above: 90 User: 90 User Mod10: 0 Computer: 10 Computer Mod10: 0 Tie game.
List the numbers in increasing order,
going down each column,
and line up the columns.
numList[0:5]
is the first 5 numbers in
numList.
numList[5:10]
is the next 5 numbers in
numList.
numList[10:15]
is the next 5 numbers in
numList.
Etc.
The yellow thing is a
conditional
expression
with one of two possible values.
The two possible values are
"\n"
and
3 * " ".
I think
3 * " "
is easier to understand than
" "
# Generate random sample of n numbers.
n = 25
numList = random.sample(range(1, 100), n)
numList.sort()
#listOfLists is a list of ncols smaller lists.
#Each smaller list contains height integers.
ncols = 5 #number of columns
height = n // ncols #how many numbers in each column
listOfLists = [numList[col * height: (col + 1) * height] for col in range(ncols)]
#Display numList in ncols columns.
for row in zip(*listOfLists): #row is a tuple containing ncols integers.
for col, num in enumerate(row):
print(f"{num:2}", end = "\n" if col % ncols == ncols - 1 else 3 * " ")
1 22 38 57 73 7 23 41 59 76 12 26 45 62 85 17 27 48 68 91 21 37 55 71 94 Select one number from above:
Please create a new repository for each Python program. Please put your repositories in your SF19PB1 organization. See steps 4 and 5.
Store your Python program in a file whose name ends with
.py.
Begin the file with a
docstring.
Indent with groups of
four
spaces,
not with tabs.
You can’t use a variable
(e.g., the
columns
in
line 3,
and the
rows
in
line 4)
until you create it.
Put one space after each comma
(line 2)
for legibility.
A
user-defined
function
will do nothing unless you call it.
End the program by calling
sys.exit.
We
saw
a loop from which we can exit in two ways:
happy and sad.
Here is another example.
We’ll get rid of the last
if
and the variable
found,
and correct the indentation.
"""
Search a list of 4 strings.
"""
import sys
# Initialize fruit list
fruit_list = ['Apples', 'Bananas', 'Carrots', 'Dates']
# Get fruit
fruit = input('Search for a fruit: ')
# Check for fruit
for f in fruit_list:
if f == fruit:
break
else:
#Arrive here if we finished all 4 iterations of the for loop.
print('No match!')
sys.exit(1)
#Arrive here if we broke out of the for loop before finishing all 4 iterations.
print('found!')
sys.exit(0)
Simpler to use the
in
operator instead of
for/if/break:
"""
Search a list of 4 strings.
"""
import sys
# Initialize fruit list
fruit_list = ['Apples', 'Bananas', 'Carrots', 'Dates']
# Get fruit
fruit = input('Search for a fruit: ')
# Check for fruit
if fruit in fruit_list:
print('found!')
sys.exit(0)
print('No match!')
sys.exit(1)
"""
graph paper.py
Makes a graph chart based on your input.
"""
import sys
rowNum = "How many rows? "
columnNum = "How many columns? "
rowSpace = "How many spaces within each row? "
colSpace = "How many spaces within each column? "
print("Hello, let's build a graph.")
print()
# Get inputs from user and entry checker
def getInt(prompt):
assert isinstance(prompt, str)
while True:
try:
s = input(prompt)
except EOFError:
sys.exit(1)
except KeyboardInterrupt:
sys.exit(1)
try:
i = int(s)
except ValueError:
print()
print("Sorry, please enter a whole number.")
else:
return i
row = getInt(rowNum)
column = getInt(columnNum)
rowSpace = getInt(rowSpace)
colSpace = getInt(colSpace)
## Code for graph printing ##
colsp = colSpace * "-"
colem = colSpace * " "
for outer in range(row):
print(f"+{colsp}" * column + "+")
for inner in range(rowSpace):
print(f"|{colem}" * column + "|")
print(f"+{colsp}" * column + "+")
sys.exit(0)
"""
graph paper.py
Makes a graph chart based on your input.
"""
import sys
#questions is a list containing 4 smallers lists.
#Each smaller list contains 2 strings.
questions = [
["rowNum", "How many rows?"],
["columnNum", "How many columns?"],
["rowSpace", "How many spaces within each row?"],
["colSpace", "How many spaces within each column?"]
]
print("Hello, let's build a graph.")
print()
dictionaryOfVariables = globals()
for question in questions:
while True:
variableName = question[0]
prompt = question[1]
s = input(prompt + " ")
try:
dictionaryOfVariables[variableName] = int(s)
except ValueError:
print()
print("Sorry, please enter a whole number.")
else:
break #out of the while loop
## Code for graph printing ##
colsp = colSpace * "-"
colem = colSpace * " "
for outer in range(rowNum):
print(f"+{colsp}" * columnNum + "+")
for inner in range(rowSpace):
print(f"|{colem}" * columnNum + "|")
print(f"+{colsp}" * columnNum + "+")
sys.exit(0)
Women's Shoe Size Conversion Table +-------+-------+-------+-------+ | UK| US| EU| Japan| +-------+-------+-------+-------+ | 3| 5| 36| 21.5| +-------+-------+-------+-------+ | 3.5| 5.5| 36.5| 22.0| +-------+-------+-------+-------+ | 4.0| 6.0| 37.0| 22.5| +-------+-------+-------+-------+ | 4.5| 6.5| 37.5| 23.0| +-------+-------+-------+-------+ | 5.0| 7.0| 38.0| 23.5| +-------+-------+-------+-------+ | 5.5| 7.5| 38.5| 24.0| +-------+-------+-------+-------+ | 6.0| 8.0| 39.0| 24.5| +-------+-------+-------+-------+ | 6.5| 8.5| 39.5| 25.0| +-------+-------+-------+-------+ | 7.0| 9.0| 40.0| 25.5| +-------+-------+-------+-------+ | 7.5| 9.5| 40.5| 26.0| +-------+-------+-------+-------+ | 8.0| 10.0| 41.0| 26.5| +-------+-------+-------+-------+ | 8.5| 10.5| 41.5| 27.0| +-------+-------+-------+-------+
Store your Python program in a file whose name ends with
.py.
Give each variable a lowercase name.
See how we needed only one induction variable in
pierogies,
thruway,
and
asciichart.
"""
ShoeSize.py
table that converts Women's shoe sizes
based off:
https://images.app.goo.gl/6vZXM9qggrCKQU8h7
"""
import sys
#The heading is a string of 5 lines, containing 2 pockets.
heading = """\
Women's Shoe Size Conversion Table
{}
| UK| US| EU| Japan|
{}
"""
UK = 3
US = 5
EU = 36
JP = 21.5
lines = 4 * "+-------" + "+"
print(heading.format(lines, lines), end = "")
for i in range(12):
print(f"|{i/2 + UK:7}|{i/2 + US:7}|{i/2 + EU:7}|{i/2 + JP:7}|")
print(lines)
sys.exit(0)
"""
ShoeSize.py
table that converts Women's shoe sizes
based off:
https://images.app.goo.gl/6vZXM9qggrCKQU8h7
"""
import sys
regions = [
["UK", 3], #United Kingdom
["US", 5], #United States
["EU", 36], #Europe
["JP", 21.5] #Japan
]
names = ""
for region in regions:
name = region[0]
names += f"|{name:>7}" #The > right justifies the name.
names += "|"
n = len(regions)
line = n * ("+" + 7 * "-") + "+"
#The heading is a string of 5 lines, containing 3 pockets.
heading = """\
Women's Shoe Size Conversion Table
{}
{}
{}
"""
print(heading.format(line, names, line), end = "")
for i in range(12):
for region in regions:
number = region[1]
print(f"|{i/2 + number:7}", end = "")
print("|")
print(line)
sys.exit(0)
A space immediately before a newline serves no purpose.
Which multiplication table would you like to look up? 3 3 * 0 = 0 3 * 1 = 3 3 * 2 = 6 3 * 3 = 9 3 * 4 = 12 3 * 5 = 15 3 * 6 = 18 3 * 7 = 21 3 * 8 = 24 3 * 9 = 27 3 * 10 = 30 Here you go!
"""
multiplicationtable.py
Multiply the selected number by 0, 1, 2, ..., 10.
"""
import sys
while True:
try:
t = input("Which multiplication table would you like to look up? ")
table = int(t)
except EOFError:
sys.exit(1)
except KeyboardInterrupt:
sys.exit(1)
except ValueError:
print("Please enter an integer.")
else:
break
for multiplier in range(11):
print(f"{table} * {multiplier:2} = {table * multiplier:2}")
print()
print("Here you go!")
sys.exit(0)
"""
Output a list of the words in an article, in order of the most frequent.
Sample output:
29 the
20 to
17 trump
12 a
12 that
etc.
"""
import sys
import string
import collections
import requests
import bs4
url = "https://www.usatoday.com/story/news/politics/2019/08/26/donald-trump-china-trade-war/2118225001"
response = requests.get(url)
soup = bs4.BeautifulSoup(response.content, features = "lxml")
punctuation = string.punctuation + "\u201C\u201D" #double quotes “ ”
listOfWords = []
for paragraph in soup.findAll("p"):
for text in paragraph.findAll(text = True):
for word in text.split():
word = word.strip(punctuation)
if word: #if word is not the empty string
word = word.lower()
listOfWords.append(word)
#Counter is like a dict. Keys are words, values are counts.
counter = collections.Counter(listOfWords)
listOfTuples = counter.most_common()
for word, i in listOfTuples:
print(f"{i:2} {word}")
sys.exit(0)
29 the 20 to 17 trump 12 a 12 that 11 in 11 on 9 chinese 9 and 8 an etc. 1 world 1 economy 1 arrived 1 dissipate 1 says 1 recently 1 photo 1 alastair 1 pike/afp/getty 1 images
Alphabetically sort each group of words that share the same frequency. In other words, sort the words in order of decreasing frequency, and break ties by using alphabetical order.
#before the last for loop listOfTuples.sort(key = lambda t: (-t[1], t[0]))
29 the 20 to 17 trump 12 a 12 that 11 in 11 on 9 and 9 chinese 8 an etc. 1 we've 1 week 1 weekend 1 well 1 what’s 1 who 1 work 1 world 1 years 1 you
Is it harder to understand if we create the
listOfWords
using a
list
comprehension?
Does it run faster?
Sorry we had to
strip
each word twice.
listOfWords = [
word.strip(punctuation).lower()
for paragraph in soup.findAll("p")
for text in paragraph.findAll(text = True)
for word in text.split()
if word.strip(punctuation)
]
In Algebra you say 2x, not x2.
c=m*(d*52-h-p)*2
workdaysPerYear = d * 52 - h - p c = 2 * m * workdaysPerYear
How many times have Liverpool been European Champions? You get 5 attempts Go ahead: 4 Wrong Go ahead: 6 Correct! You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone You'll Never Walk Alone
"""
Guessing game. You get only 5 tries before it tells you the correct answer.
"""
import sys
instructions = "How many times has Liverpool been European Champions? You get 5 attempts"
print(instructions)
for i in range(5):
guess = input("Go ahead: ")
n = int(guess)
if n == 6:
print("Correct!")
for i in range(9):
print("You'll Never Walk Alone")
sys.exit(0)
print("Wrong")
print("The correct answer is 6.")
sys.exit(1)
"""
Guessing game. You get only 5 tries before it tells you the correct answer.
"""
import sys
instructions = "How many times has Liverpool been European Champions? You get 5 attempts"
print(instructions)
for i in range(5):
guess = input("Go ahead: ")
n = int(guess)
if n == 6:
break
print("Wrong")
else:
#Arrive here after looping 5 times (i.e., after exhausiting the loop).
print("The correct answer is 6.")
sys.exit(1)
#Arrive here after breaking out of the loop with the break statement.
print("Correct!")
for i in range(9):
print("You'll Never Walk Alone")
sys.exit(0)
Welcome to Pie-thon Pizza recipes! The best pies in the city, located at 25 Broadway! Here's some frequently asked quesitons: A) How many slices of pepperoni will I need? B) How many pizzas do I need to feed 'x' amount of people? C) How many days until Pie Day? Choose from the above, type A, B, or C B One pizza can feed around four people. How many people do you have? 5 To feed 0 people you would need 0 pizza. To feed 1 people you would need 0 pizza. To feed 2 people you would need 0 pizza. To feed 3 people you would need 0 pizza. To feed 4 people you would need 1 pizza. To feed 5 people you would need 1 pizza.
"""
Pie-thon.py
Answers frequently asked questions
"""
import sys
import math
import datetime
#Each question ends with one space.
menu = """\
Welcome to Pie-thon Pizza recipes! The best pies in the city, located at 25 Broadway!
Here are some frequently asked quesitons:
A) How many slices of pepperoni will I need?
B) How many pizzas do I need to feed 'x' amount of people?
C) How many days until Pie Day?
Choose from the above, type A, B, or C: """
howManyPizzas = """\
Our ratio is 10 pepperonis to one pizza.
How many pizzas are you making? """
howManyPeople = """\
One pizza can feed around four people.
How many people do you have? """
option = input(menu)
option = option.lower() #Can combine to option = input(menu).lower()
print() #Skip an empty line.
if option == "a":
pepperoni = int(input(howManyPizzas))
for p in range(1, pepperoni + 1):
print(f"To make {p:2} pizza(s), you will need {10*p:3} slices of pepperonis.")
elif option == "b":
people = int(input(howManyPeople))
for ppl in range(1, people+1):
print(f"To feed {ppl} people you would need {math.ceil(ppl/4)} pizza(s).")
elif option == "c":
today = datetime.datetime.today() #an object of type datetime
year = today.year
pieDay = datetime.datetime(year, 3, 14) #another object of type datetime
if today > pieDay: #Have we already passed this year's Pie Day?
pieDay = datetime.datetime(year + 1, 3, 14) #use next year's Pie Day
delta = pieDay - today #distance between two datetimes
print(f'{delta.days} days until Pie Day ({pieDay.strftime("%-m/%-d/%Y")})!!')
else:
print("Error: you did not press A, B, or C. Goodbye!")
sys.exit(1)
sys.exit(0)
If you’re 1985 miles from Los Angeles, then your time to destination should be 3.97 hours, not 4.97 hours. And instead of 3.97 hours, the user would rather see 3 hours and 58.2 minutes. What happens if you select city number zero?
--------------- | Flight Time | --------------- Select destination: [1] Los Angeles LAX [2] Chicago ORD [3] Houston IAH [4] Phoenix PHX [5] Orlando MCO Enter Destination Number: 1 Flight distance: 2485.54 Air speed: 500 miles per hour Distance to destination: 1985 miles Time to destination: 4.97 hours Distance to destination: 1485 miles Time to destination: 3.97 hours Distance to destination: 985 miles Time to destination: 2.97 hours Distance to destination: 485 miles Time to destination: 1.97 hours
Translate to Spanish?
"""
Prompt user for a flight destination and display the distance/time to their
destination.
Created: 2019-08-21
"""
import sys
heading1 = """\
---------------
| Flight Time |
---------------
Select destination:"""
heading2 = """\
Flight distance: {}
Air speed: {} miles per hour
"""
print(heading1)
#A list containing 5 smaller lists. Each smaller list contains 3 items.
cities = [
["LAX", "Los Angeles", 2485.54],
["ORD", "Chicago", 738.02],
["IAH", "Houston", 1426.18],
["PHX", "Phoenix", 2148.15],
["MCO", "Orlando", 945.51]
]
for i, city in enumerate(cities):
print(f"[{i + 1} {city[1]:11} {city[0]}")
destinationNum = int(input("Enter Destination Number: "))
destinationNum -= 1
n = len(cities)
if destinationNum not in range(n):
print(f"Invalid destination! Must be in range 1 to {n}.")
sys.exit(1)
flightDist = cities[destinationNum][2]
airSpeed = 500
print(heading2.format(flightDist, airSpeed)) #We saw format in Thruway example.
flightDist = int(flightDist)
for m in range(flightDist, 0, -airSpeed):
print(f"Distance to destination: {m:,} miles")
print(f"Time to destination: {m / airSpeed:.2f} hours")
print()
sys.exit(0)
Install Beautiful Soup. Lambda functions.
"""
Print all the Facebook and Twitter links in a web page.
"""
import sys
import re #regular expression
import urllib.request
import bs4 #beautiful soup
url = input("Please enter the name of the website you would like to find social media sites for: ")
try:
response = urllib.request.urlopen(url)
except urllib.error.URLError as error:
print(f"urllib.error.URLError: {error}")
sys.exit(1)
soup = bs4.BeautifulSoup(response, "html.parser")
response.close()
reg = r"^https://(www\.)?(facebook|twitter)\.com"
for anchor in soup.find_all("a", href = lambda url: re.search(reg, str(url))):
print(anchor["href"])
sys.exit(0)